つよつよエンジニアになるには?~データに強いエンジニアは強い~
背景
プログラミングを勉強しはじめて膨大な勉強量に打ちのめされそうになった経験はあるかと思います。その一つにデータベースがあります。 以前職場でもベテランエンジニアの方が「最近の若いやつはSQLも書けん!」と言っていたのを思い出しました。
一昨年サンフランシスコ、シアトルで2週間ほど一人旅していました。当時エンジニアとして伸び悩んでいた僕は「日本でも抜きん出たエンジニアになるにはどうしたらいいですか?」という質問をシリコンバレーで働くあらゆる企業の方に聞いてまわりました。その中のひとりにFacebookのソフトウェアエンジニアの方がおり、お話しする機会がありました。僕の質問に対しての回答はこのようなものでした。
データに強くなったほうがいい。フロントは5年単位でどんどん変わっていくけど、データは変わらないから。
Design Docって知ってる?クラス図とかオブジェクト図は絶対かけたほうがいいよ。
オブジェクト指向で設計したデータモデルをどう効率よく処理するかは、たいていORMが面倒見てくれるのであまり意識しないけど、裏側の仕組みを理解しておくといいよ。
その後、データの見方が変わりましたし、クラス図とオブジェクト図に関してはUMLの勉強をして学びました。データに強くなるとなんでも設計できそうな感覚が身についてきました。設計できればあとは実装するだけです。最初は設計と実装にも乖離があり、実装し始めると困ることもありますが、だんだんと設計と実装が一致してきます。
こういったこともあって「データに強いエンジニアは強々エンジニアになりやすい」という仮設を立てました。
成長している企業はデータを保持している企業ですし。
またこの記事でアウトプットするようにしたのは主に自分のためですが、この記事を踏み台にしてデータベースに強くなっていくことによって日本に強々エンジニアを増やしたいというのがあってのことです。チュートリアルでもハンドブックでもバイブルでもないですが、ここで出てきた新しい知識を調べていくときに良書に出会えるし、関連知識が増していくといいな思います。
前置きが長くなりましたが、ここから本文です。
データベースの歴史は長いので現代のデータベースにフォーカスするなら飛ばしてもらって大丈夫です。
目次
データベースの歴史
この記事を読む人はみなデータベースがどういったものであるかはわかっているかと思いますが、知らない人でもATMからお金を引き出したり、銀行の残高を確認したり、オンラインで買い物をしたり、ソーシャルメディアを表示したり、ほとんどすべてのデジタル機器を操作するときは、データベースにアクセスしています。
データベースの初期の歴史
データベースが存在する前は、すべてを紙に記録する必要がありました。本棚に積まれる数十万または数百万ものレコードを含むリスト、新聞記事、雑誌、元帳、および無限のアーカイブがありました。これらの中から1つのレコードにアクセスする必要がある場合、レコードを見つけて物理的に取得することは、時間と労力を要する作業でした。書類の置き忘れから、掃除から火災までさまざまな問題がしばしば発生しました。物理的なアクセスは簡単に取得できることが多いため、セキュリティの問題もありました。
データベースは、従来の紙ベースの情報ストレージのこういった課題を解決するために作成されました。データベースでは、ファイルはレコードと呼ばれ、レコード内の個々のデータ要素(名前、電話番号、生年月日など)はフィールドと呼ばれます。これらの要素の保存方法は、データベースの初期の頃から進化してきました。
初期のシステムは、階層モデルおよびネットワークモデルと呼ばれていました。階層モデルは、図に示すように、ツリー構造でデータを整理しました。IBMは1960年代にこのモデルを開発しました。

階層モデルの各レコードには、ルートレコードから始まる親レコードがあります。会社、学校のような組織が現実世界に多くあるので理解しやすいモデルでした。階層モデルのレコードには一つのフィールドが含まれていました。このモデルを使用してデータにアクセスするには、ツリー全体を横断する必要がありました。これらのタイプのデータベースは現在も存在しており、テクノロジーが大幅に進歩したにもかかわらず、開発現場があるそうです。ただし、多くの欠点もあります。主な点は、データタイプ間の関係を簡単に表すことができないということです。それによって、データの冗長、重複が生じました。これは非常に複雑な方法(「ファントム」レコードを使用する方法)で実現できますが、これを実現するにはかなりの熟練者でないと扱うのが困難でした。
階層型データベースは、紙ベースの情報ストレージの問題の多くを解決しました。レコードにはほぼ瞬時にアクセスできます。また、完全なバックアップとリカバリのメカニズムを備えていたため、損傷によるファイルの損失という問題は過去のものとなりました。
階層モデルとネットワークモデルの主な違いは、ネットワークモデルでは、各レコードに複数の親レコードと子レコードを含めることができることです。ネットワークモデルにより、エンティティは現実世界と同じような関係性を持つことができます。例えば、顧客が店に入って製品を購入する場合、注文には顧客、オーナー、および労働者が関与します。 ネットワークモデルは階層モデルを改善しましたが、シェアが広がることはありませんでした。これの主な理由は、IBMが階層モデルを引き続き使用し、より確立されたリレーショナルモデルを考案したからです。リレーショナルモデルは設計者にとってはるかに理解しやすく、プログラミングとの相性も優れていました。ネットワークモデルと階層モデルは、パフォーマンスが向上したため、1960年代から70年代にかけて使用されました。60年代と70年代に使用されたメインフレームコンピュータシステム(図3に示す)は、ハードウェアが非常に限られていたため、可能な限り最速のソリューションを必要としていました。しかし、1980年代にはコンピューティング技術が飛躍的に進歩し、ここでおなじみのリレーショナルモデルが登場し、最も人気を博し始めました。
リレーショナルモデルは名前の通りテーブル同士の関係性を定義することができます。
- 1対1
- 1対多
- 多対多
ほとんどのリレーショナルデータベースは、データにアクセスするための標準的な方法である構造化照会言語(SQL)を使用します。SQLを使用すると、アプリケーションはユーザーが必要とするデータにアクセスできます。
1980〜1990年
リレーショナルモデルは1960年代後半に作成されて以来、ほとんど変わっていません。現代の企業は今でもこれらのシステムを使用して、日々の活動を記録し、重要な戦略的意思決定を支援しています。データベース企業は世界で最大かつ最も収益性の高い組織の1つであり、1960年代と70年代に設立された企業は今日でも繁栄しています。 従来のデータベースのキー識別子は、データベースが処理するデータのタイプです。これには、一貫性があり、基本的な性質が時間の経過とともに大幅に変化しないデータが含まれています。何十年もの間、最も複雑なタイプのデータストレージを除くすべてのストレージに十分すぎるほどでした。
1977年、Larry Ellison、Bob Miner、Ed Oatesは、IBMのSystem Rデータベース(SQLの最初の実装)について読んだ後、カリフォルニアにSoftware Development Laboratories(SDL)という会社を設立しました。彼らはSystemRと互換性のあるデータベースの作成を目指しました。1979年にこの会社はRelationalSoftware、Inc(RSI)に改名され、1982年に最終的にOracle SystemsCorporationに改名されました。Oracleは今後も最大かつ最も収益性の高いデータベースベンダーになります。世界。彼らはCプログラミング言語を使用してソフトウェアを開発しました。これは、高性能であり、Cをサポートする任意のプラットフォームに移植できることを意味します。 1980年代までに、市場での競争は激化したが、オラクルは引き続き企業を支配していた。80年代の終わりに向けて、MicrosoftはSQL Server1.0と呼ばれるOS / 2プラットフォーム用のデータベースを開発しました。1993年に、これをWindows NTプラットフォームに移植し、当時のWindowsテクノロジの採用により、中小企業の標準となりました。マイクロソフトが90年代半ばから後半に作成した開発環境(Visual Basic、次に.NET)は、長年の経験を積んだ開発者だけでなく、誰でもアプリケーションでデータベースの力を利用できることを意味しました。1998年までに、彼らはSQL Server V7をリリースし、製品は市場でより確立されたプレーヤーと競争するのに十分成熟しました。
90年代初頭には、少なくともオンライン市場では、他のどのデータベースよりも大きな影響を与える別のデータベースが作成されました。1990年代半ばには、ソフトウェア開発に革命が起こりました。それは、90年代にほとんどのPCシステムで使用されていたコードのマイクロソフトの支配と厳格な管理に対抗するために起こり、オープンソース運動が生まれました。彼らはプロプライエタリの商用ソフトウェアを信じず、代わりに無料で配布可能なソフトウェアを開発しました(そしてコードを公開しました)。1995年に、MySQLの最初のバージョンがスウェーデンの会社(オープンソースプロジェクトに資金を提供した)によってリリースされました— MySQLAB。このソフトウェアはインターネットの最初の重要なデータベースであり、Google(検索用ではありませんが)、Facebook、Twitter、Flickr、Youtubeなどの企業で引き続き使用されています。オープンソースライセンスは、Webサイト開発者に自由を与え、OracleやMicrosoftなどの企業に依存する必要がないことを意味しました。また、今日使用しているインターネットの基盤を作成した他のオープンソースソフトウェアともうまく機能しました(Linux、Apache、MySQL、PHP(LAMP)がWebサイトの最も一般的なセットアップになりました)。MySQL AB(MySQLプロジェクトを後援した会社)は最終的にSun Microsystemsに買収され、その後Oracleに買収されました。 その後数年で、他の多くのオープンソースデータベースが作成されました。OracleがMySQLを買収したとき、MySQLプロジェクトの創設者はプロジェクトのフォークを作成しました(つまり、彼はコードを取得して、別の名前で新しいプロジェクトを開始しました)。この新しいプロジェクトはMariaDBと呼ばれていました。現在、さまざまなライセンスとイデオロギーを持つ多数のオープンソースデータベースがあります。
2000年以降とNoSQL
この記事のこれまでのところ、言及されているすべてのデータベースは、データベースにデータを取得して格納するための主な方法として構造化照会言語(SQL)を使用しています。1998年に、新しい用語、つまりNoSQLが作成されました。これは、他のクエリ言語を使用してデータを格納および取得する「SQLだけでなく」データベースを指します。これらのタイプのデータベースは1960年代から存在していましたが、テクノロジーの世界で注目を集めたのはWeb2.0革命でした。 Web 1.0は、ユーザーがWebマスターとそのチームによって作成されたコンテンツを受信して取り込んだときのインターネットの最初の反復でした。Web 2.0は、ユーザー生成コンテンツへの移行であり、すべての人にとってよりユーザーフレンドリーなインターネットでした。Youtubeやソーシャルメディアのようなサイトは、インターネットのこの段階を象徴しています。データベースの場合、それは開発者と管理者のニーズが変化したことを意味しました。ユーザーによって毎秒膨大な量のデータがインターネットに追加されていました。クラウドコンピューティングは、大規模なストレージと処理機能のロックを解除し、データベースの使用方法が変化しました。 このテクノロジーの時代では、新しいインターネットの性質が大幅に拡大しているため、要件は設計とスケーラビリティに関する単純さへとシフトしました。また、24時間年中無休の可用性と速度が最も重要になったことが不可欠でした。従来のリレーショナルデータベースは、特に必要なスケーラビリティと速度に苦労し、NoSQLがさまざまなデータ構造(つまり、キー値、グラフ、ドキュメント)を使用しているため、一般的に高速でした。また、従来のリレーショナルデータベースと同じ制約がなかったため、より柔軟であると見なされていました。 NoSQLにはいくつかの欠点がありました。特に、テーブル間で結合を使用できず、標準化されていませんでした。ただし、新世代のWeb開発者にとっては、NoSQLの方が優れていました。これは、21世紀の最初の20年間に行われた大規模なイノベーションの主な理由のひとつでした。これは、ウェブサイト(およびその後のアプリ)の開発がはるかに簡単になり、ワールドワイドウェブの成長する性質に対処できるためです。リレーショナルデータベースは、オンラインの世界でそれらから離れたにもかかわらず、その地位を維持し続けました。企業は、ビジネスシステムのプログラミングの信頼性、一貫性、および容易さを依然として必要としていました。
データベースの種類
コンピュータ技術の発展はいつも資本主義のプラットフォーム上で行われてきました。つまり、ビジネスになるものは技術発展したし、お金にならない研究はだんだんと収束していきます。実際に様々なデータベースの種類がありましたが、その中でもRDBが栄えたのはビジネスロジックに組み込みやすかったからです。 これからもビジネスに組み込める形のデータベースは多くの企業で使用されていくと思いますが、その点RDBは現実世界をそのまま表現できるためRDBは数十年の単位では消えないと思っています。
ここでは企業に使われるようになっているデータベースの種類を紹介したいと思います。
- RDB
- NoSQL
- ドキュメント指向型
- キー・バリュー型
- グラフ型
- カラム指向型
- NewSQL
RDB
データベースの歴史もかなり早い段階から出てきましたが、シェア率も80%を超えています。(DB-Engines Rankingより)現実世界で生活している人にとって理解しやすいモデルだと思うので、詳細な説明は省きます。なにかしらのおすすめだと言われている本を一冊読み込むのがいいでしょう。
一番一般的ではありますが、もちろんRDBにも欠点があります。RDBは書き込みの大量リクエストに弱いです。その課題を解決しようということで次のNoSQLが開発されました。
NoSQL
NoSQLは「SQLではない」ではなく、Not only SQLで「SQLだけではない」という意味です。つまり、RDBではないSQLの総称として呼ばれているのでNoSQLだけでも種類が豊富で理解に少し時間がかかると思います。
種類が多いのでデータモデルとアーキテクチャの観点で分類すると参考記事にもある通りこのように分類することができます。
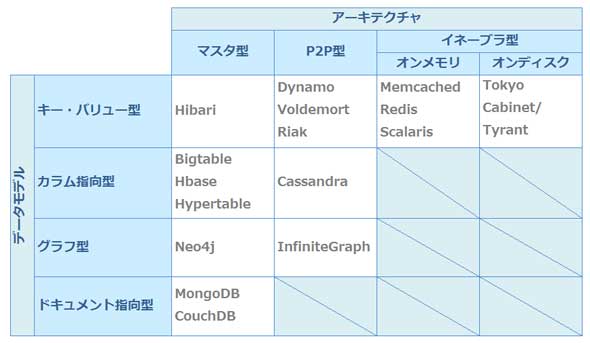
出典:KVS系NoSQLのまとめ(Hibari、Dynamo、Voldemort、Riak編)
ドキュメント指向型
ドキュメント指向のNoSQLデータベース(CouchDB、MongoDB)編 開発者が知っておくべき、ドキュメント・データベースの基礎
ドキュメント指向型は、パフォーマンス、大量データ、スケーラブルといった課題を克服するためのシンプルなセットを提供しており、JSONやXMLのような構造であるドキュメントにさまざまな型のオブジェクトをそのまま登録できるというRDBとは異なる特徴を持っています。
キー・バリュー型
KVS系NoSQLのまとめ(Hibari、Dynamo、Voldemort、Riak編)
キー・バリュー型のデータモデルは、キーとバリューの組み合わせでデータを書き込み、キーによりバリューを読み出すというシンプルな構造です。ただし、そのアーキテクチャは複数あり、大きく分けてマスタ型とP2P型があります。アーキテクチャはこのいずれかなのですが、ここではあえて、第3の分類としてイネーブラ型という類型を設け、その特徴を明らかにします。
イネーブラ型のNoSQLデータベースは、単体でも利用できます。実際に単体で利用されるケースが多いのですが、他のデータベースと組み合わせたときに、特段の利用効果を発揮するという特性を持ったソフトウェアです。「他のデータベース」とは、SQLデータベース、永続性を提供するNoSQLデータベース、拡張性を提供するNoSQLデータベースのことです。
イネーブラ型はさらに、「オンメモリ」タイプと「オンディスク」タイプに分けられます。オンメモリタイプはデータの永続性を保証しません。メモリ上で動作するので、性能面では高速処理ができるものの、サーバの電源を切ってしまえばデータが消失してしまいます。一方、オンディスクタイプは、データをハードディスクに書き込むことでデータの永続性を保証するものの、複数のサーバにデータベースを分割して保有するという拡張性を有しません。
グラフ型
グラフ型NoSQLデータベース(Neo4j、InfiniteGraph)編 グラフデータベースはどんな用途に向いている?
グラフデータベースとは、「ノード」「リレーション」「プロパティ」の3要素によってノード間の「関係性」を表現する「グラフ型のデータモデル」を持つデータベースといえます。
リレーショナルデータベースではないため「NoSQL」に分類されますが、この「グラフ型のデータモデル」とは、NoSQLといったときに一般的に想起される「KVS(キーバリューストア)型データベース」や「MongoDB」のような「ドキュメント指向データベース」とは異なるデータモデルとなります。
Facebookの知り合いかも機能や複雑なデータの探索に有効的です。グラフ理論のグラフですね。
カラム指向型
カラム指向型データベース(HBase、Hypertable、Cassandra)編
RDBは行指向のデータベースであり、1つ1つの行をひとかたまりのデータとして扱います。それに対して、カラム型データベースは列方向にデータを扱います。そのため、特定の列の値をまとめて処理することに非常に長けています。列単位での大量集計、大量更新が得意で、逆に特定の行を抜き出して更新したり削除したりするのは苦手です。
HBaseとHypertableはGoogleのBig-tableに触発されたマスタ型であり、CassandraはBigtableとAmazon Dynamoのハイブリッドとして開発され、P2P型に分類されます。
NewSQL
最近話題になりやすいNewSQLについてです。 NewSQLは名の通り一番新しいデータベースでRDBとNoSQLのいいとこ取りをしたような設計になっています。RDBのSQLとNoSQLの性能を同時に採用しました。RDBの性能改善としてSQLを崩した状態でNoSQLを開発し、結局SQL使いとのことでNewSQLの需要が生まれました。
有名どころはGoogle Cloud SpannerやCockroachDBなどがあります。 ちなみにCockroachDBはRDB要素があるのでPostgresQLと互換性があります。
データベースの種類まとめ

SQLについて
もしあなたが
select, create, insert, dropしか使えない
という状況でしたらぜひ一度SQLを体系的に学んでみることをおすすめします。SQLの万能さに驚くと思います。通常のCRUDアプリくらいならCRUDレベルのSQLしか使わないですが、もっといろんな事ができます。僕は以前う受けていた案件で「〇〇したときの〇〇な〇〇のユーザーの情報を取得するSQL作っといて」と複雑な条件が絡んだ課題を課せられたときにSQL力が伸びました。
CRUDしか使っていないならJOINから始めて条件文の作り方やGROUP BY、TRANSACTIONなどを学んでいくといいと思います。SQLを自分で作れることでWebサービスをより効率的に開発することができます。普段RailsやLaravelなどの高機能フレームワークを使用する場合はORM(オブジェクトリレーショナルマッパー)というありがたい存在によってあまり気にしないですが、普段書いているコードは結局はORMでSQLに変換されています。
例えばRailsの場合
User.where(city: 'Tokyo') # SELECT "users".* FROM "users" WHERE "users"."city" = ? [["city", "Tokyo"]] # 簡略化すると # SELECT * FROM users WHERE city = "TOKYO"
のようなSQLが発行されます。これをわかってみるとコード上きれいに見えても発行されているSQLを見るとものすごく効率が悪いという場合があったりします。SQLを学ぶメリットとしてSQLを意識したプログラミングができるようになると思います。
ORMについて
ORMについてActive Recordがかなり優秀だと思いますので、Active RecordのWikiを見るとかなり勉強になると思います。今更意識しないですが、中身でどう動いてるのか学ぶことには意味があると思います。もっと実感したいならORMなしで開発してみるのもいいかもしれないですね。 Active Record
設計について
良い設計というのは時と場合によるものです。しかし、悪い設計というものはいかなる状況においても許されるものではありません。であれば悪い設計、つまりアンチパターンを覚えることがキーになってきます。 アンチパターンといばこの本です。みな一度は読んでいるんじゃないでしょうか。
スケーラビリティとは?
システム開発におけるスケールとはシステムキャパシティを広げるという意味で用いられます。スケーラビリティはシステムの拡張性、拡張可能性という意味です。
スケール方法については「垂直」「水平」のどちらかの方向にスケールする2種類があります。
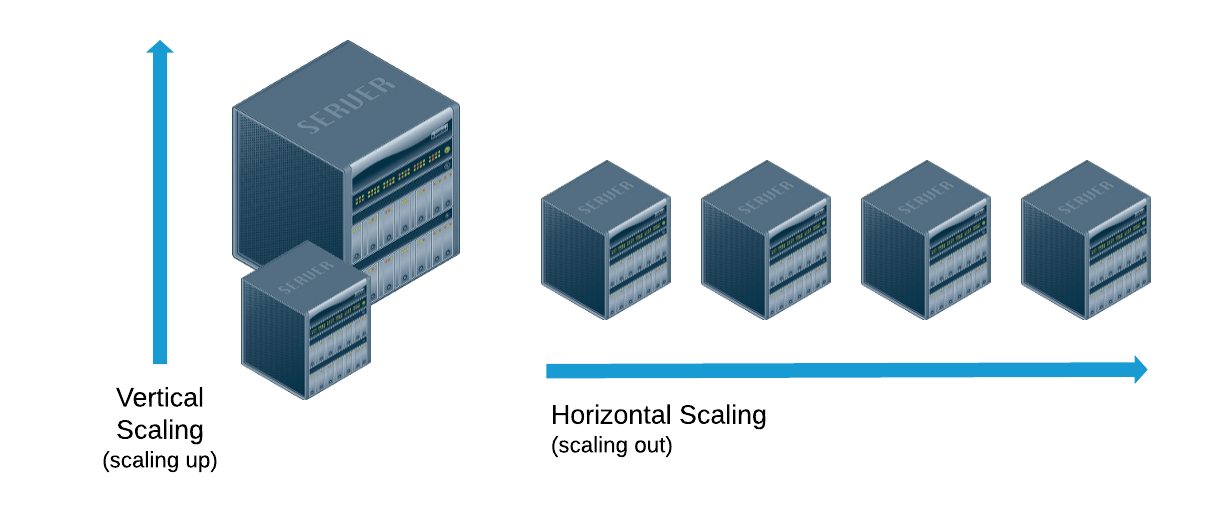
出典:Scaling Horizontally vs. Scaling Vertically
垂直方向のスケール
既存のマシンのCPU、RAMの性能を向上させることにより、キャパシティを広げます。最近のIaasだとボタン一つでスケールアップすることができます。
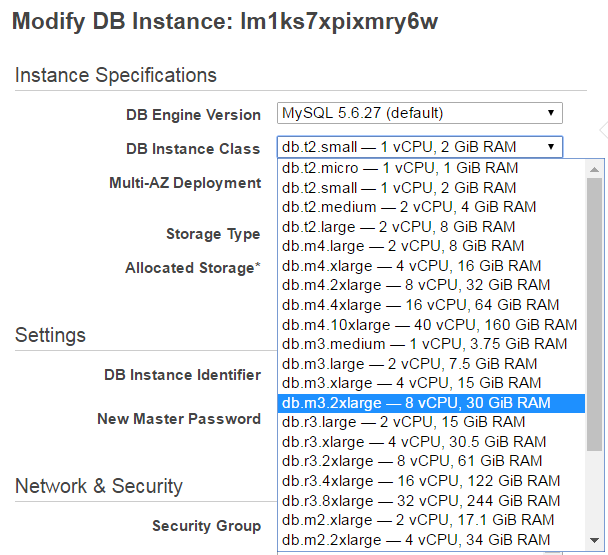
出典:Scaling Your Amazon RDS Instance Vertically and Horizontally
RDBをスケールする際は垂直スケーリングが多いです。また、何気なく使っていましたが、垂直方向にスケールすることをスケールアップ、スペックを下げることをスケールダウンといいます。垂直スケーリングは1台のマシンの容量に制限され、その容量を超えてスケーリングするとダウンタイムが発生する可能性があり、ハードウェアの上限、つまり現在実行しているハードウェアのスケールがあります。
水平方向のスケール
サーバの台数を増やすことにより、キャパシティを広げます。水平方向にスケールすることをスケールアウト、サーバ台数を減らすことをスケールインといいます。理論的には、既存のプールにマシンを追加すると、単一ユニットの容量に制限されず、より少ないダウンタイムで拡張できるようになります。
NoSQLは水平スケーリングがしやすい設計になっています。逆に言うとRDBを水平スケーリングする場合は高度な技術が必要になります。いいとこ取りのNewSQLはリレーションを持ちながらも水平スケーリングも可能な設計になっています。
スケールアウトのアプローチはいくつかあります。
シャーディング(水平分割)
シャーディングは、大量のデータを複数のデータベースに分割することで負荷を分散する手法です。スケールしたアプリケーションサーバからの同時接続数が限界であったり、巨大なデータを扱う際にbufferが溢れDisk/IOが発生する際にこの手法で対処することが多いです。
レプリケーション
レプリケーションとはハードウェアを含め同じシステム環境が2セット(稼働系と待機系)用意された環境において リアルタイムにデータ複製する技術です。万が一、稼働系に障害が発生した時にも、待機系に切り替えるだけで業務を継続することができます。スケールアウトアプローチの中でも実装が一番容易です。
バックアップと何が違うのと思いますが、バックアップはある時点(静止点)のファイルやアプリケーション、およびそれらを含むシステム全体を別の場所に保存する事です。レプリケーションはより動的でバックアップはより静的です。
最後に
思ったよりも豊富な情報量になってしまいましたが、ここで得てほしいのは単語です。なるべく初心者にわかりにくいようなボキャブラリーを選択しました。この記事で説明するようなことはあえてせず、この記事を読むことでわからない単語を知って調べて見るところから始め、この記事で言っていることがだいたい理解できるようになったら一人前のエンジニアです。
正直まだぼくも「データベース得意です!」と言えるほど自身はありません。この世の中にはデータベースエンジニアなる人達がいます。CockroachDBで働いている人の技術記事やDB Weeklyを購読して読むとさらに込み入った話が出てきます。
今年初の記事ですので、今年もどうぞよろしくお願いいたします。