人は病だと思うとちょっとだけ優しくなれる。
大量のwordをpythonで自動化してデータベースに変換してみた
こんにちは。
教会エンジニアのSatoruです。
今回は教会でのDX事例を紹介します。
- 開発までの経緯
- 開発中に起きた課題
- 課題1: m1でpython-docxが動かない
- 課題2: wordファイルが古い
- 課題3: タイトルの日付の形式がバラバラ&変な文字入ってる
- 結果
開発までの経緯
まず前提として知っておいてほしいのですが、
神様が話される言葉を「御言葉(みことば)」と言います。
この御言葉、つまりは聖句や箴言などをまとめておくのにwordを使っていました。
それを以前開発した情報集約サイトにアップしたいとのことでした。
そしたらWeb上でみんながその御言葉を読めたりするのでかなり便利です。
これをどうにかしてできないかという相談がありました。
依頼主は「それが技術的に難しいならもういっそのこと全部コピペして頑張るよ!」という恐ろしいやる気の持ち主でした。wordファイルは2000を超えていたのです。
それは技術者として絶対にさせまいとコードを書くに至りました。
もう少し具体的にはタイトルの通り、「2000を超えるwordファイルを自動的に読み取って情報集約サイトのデータベースに挿入する」ようになりました。
続きを読む
はじめまして、わたしが教会エンジニアです。
こんにちは。
教会エンジニアのsatoruです。
以前やっていた独自ブログからはてぶにお引越ししました。
エディタでブログ書いて、Gitでコミットしてプッシュするというただでさえハードルが高いブログにハードルを重ねて活動してました。(やめてよかった)
こっちのほうが圧倒的楽にブログ配信できるのでこまめにやっていこうかなという所存です。
ブログはQiitaを使うのか、ブログを使うのか問題でだいぶ迷いましたが、
続きを読むつよつよエンジニアになるには?~データに強いエンジニアは強い~
背景
プログラミングを勉強しはじめて膨大な勉強量に打ちのめされそうになった経験はあるかと思います。その一つにデータベースがあります。 以前職場でもベテランエンジニアの方が「最近の若いやつはSQLも書けん!」と言っていたのを思い出しました。
一昨年サンフランシスコ、シアトルで2週間ほど一人旅していました。当時エンジニアとして伸び悩んでいた僕は「日本でも抜きん出たエンジニアになるにはどうしたらいいですか?」という質問をシリコンバレーで働くあらゆる企業の方に聞いてまわりました。その中のひとりにFacebookのソフトウェアエンジニアの方がおり、お話しする機会がありました。僕の質問に対しての回答はこのようなものでした。
データに強くなったほうがいい。フロントは5年単位でどんどん変わっていくけど、データは変わらないから。
Design Docって知ってる?クラス図とかオブジェクト図は絶対かけたほうがいいよ。
オブジェクト指向で設計したデータモデルをどう効率よく処理するかは、たいていORMが面倒見てくれるのであまり意識しないけど、裏側の仕組みを理解しておくといいよ。
その後、データの見方が変わりましたし、クラス図とオブジェクト図に関してはUMLの勉強をして学びました。データに強くなるとなんでも設計できそうな感覚が身についてきました。設計できればあとは実装するだけです。最初は設計と実装にも乖離があり、実装し始めると困ることもありますが、だんだんと設計と実装が一致してきます。
こういったこともあって「データに強いエンジニアは強々エンジニアになりやすい」という仮設を立てました。
成長している企業はデータを保持している企業ですし。
またこの記事でアウトプットするようにしたのは主に自分のためですが、この記事を踏み台にしてデータベースに強くなっていくことによって日本に強々エンジニアを増やしたいというのがあってのことです。チュートリアルでもハンドブックでもバイブルでもないですが、ここで出てきた新しい知識を調べていくときに良書に出会えるし、関連知識が増していくといいな思います。
前置きが長くなりましたが、ここから本文です。
データベースの歴史は長いので現代のデータベースにフォーカスするなら飛ばしてもらって大丈夫です。
目次
データベースの歴史
この記事を読む人はみなデータベースがどういったものであるかはわかっているかと思いますが、知らない人でもATMからお金を引き出したり、銀行の残高を確認したり、オンラインで買い物をしたり、ソーシャルメディアを表示したり、ほとんどすべてのデジタル機器を操作するときは、データベースにアクセスしています。
データベースの初期の歴史
データベースが存在する前は、すべてを紙に記録する必要がありました。本棚に積まれる数十万または数百万ものレコードを含むリスト、新聞記事、雑誌、元帳、および無限のアーカイブがありました。これらの中から1つのレコードにアクセスする必要がある場合、レコードを見つけて物理的に取得することは、時間と労力を要する作業でした。書類の置き忘れから、掃除から火災までさまざまな問題がしばしば発生しました。物理的なアクセスは簡単に取得できることが多いため、セキュリティの問題もありました。
データベースは、従来の紙ベースの情報ストレージのこういった課題を解決するために作成されました。データベースでは、ファイルはレコードと呼ばれ、レコード内の個々のデータ要素(名前、電話番号、生年月日など)はフィールドと呼ばれます。これらの要素の保存方法は、データベースの初期の頃から進化してきました。
初期のシステムは、階層モデルおよびネットワークモデルと呼ばれていました。階層モデルは、図に示すように、ツリー構造でデータを整理しました。IBMは1960年代にこのモデルを開発しました。

階層モデルの各レコードには、ルートレコードから始まる親レコードがあります。会社、学校のような組織が現実世界に多くあるので理解しやすいモデルでした。階層モデルのレコードには一つのフィールドが含まれていました。このモデルを使用してデータにアクセスするには、ツリー全体を横断する必要がありました。これらのタイプのデータベースは現在も存在しており、テクノロジーが大幅に進歩したにもかかわらず、開発現場があるそうです。ただし、多くの欠点もあります。主な点は、データタイプ間の関係を簡単に表すことができないということです。それによって、データの冗長、重複が生じました。これは非常に複雑な方法(「ファントム」レコードを使用する方法)で実現できますが、これを実現するにはかなりの熟練者でないと扱うのが困難でした。
階層型データベースは、紙ベースの情報ストレージの問題の多くを解決しました。レコードにはほぼ瞬時にアクセスできます。また、完全なバックアップとリカバリのメカニズムを備えていたため、損傷によるファイルの損失という問題は過去のものとなりました。
階層モデルとネットワークモデルの主な違いは、ネットワークモデルでは、各レコードに複数の親レコードと子レコードを含めることができることです。ネットワークモデルにより、エンティティは現実世界と同じような関係性を持つことができます。例えば、顧客が店に入って製品を購入する場合、注文には顧客、オーナー、および労働者が関与します。 ネットワークモデルは階層モデルを改善しましたが、シェアが広がることはありませんでした。これの主な理由は、IBMが階層モデルを引き続き使用し、より確立されたリレーショナルモデルを考案したからです。リレーショナルモデルは設計者にとってはるかに理解しやすく、プログラミングとの相性も優れていました。ネットワークモデルと階層モデルは、パフォーマンスが向上したため、1960年代から70年代にかけて使用されました。60年代と70年代に使用されたメインフレームコンピュータシステム(図3に示す)は、ハードウェアが非常に限られていたため、可能な限り最速のソリューションを必要としていました。しかし、1980年代にはコンピューティング技術が飛躍的に進歩し、ここでおなじみのリレーショナルモデルが登場し、最も人気を博し始めました。
リレーショナルモデルは名前の通りテーブル同士の関係性を定義することができます。
- 1対1
- 1対多
- 多対多
ほとんどのリレーショナルデータベースは、データにアクセスするための標準的な方法である構造化照会言語(SQL)を使用します。SQLを使用すると、アプリケーションはユーザーが必要とするデータにアクセスできます。
1980〜1990年
リレーショナルモデルは1960年代後半に作成されて以来、ほとんど変わっていません。現代の企業は今でもこれらのシステムを使用して、日々の活動を記録し、重要な戦略的意思決定を支援しています。データベース企業は世界で最大かつ最も収益性の高い組織の1つであり、1960年代と70年代に設立された企業は今日でも繁栄しています。 従来のデータベースのキー識別子は、データベースが処理するデータのタイプです。これには、一貫性があり、基本的な性質が時間の経過とともに大幅に変化しないデータが含まれています。何十年もの間、最も複雑なタイプのデータストレージを除くすべてのストレージに十分すぎるほどでした。
1977年、Larry Ellison、Bob Miner、Ed Oatesは、IBMのSystem Rデータベース(SQLの最初の実装)について読んだ後、カリフォルニアにSoftware Development Laboratories(SDL)という会社を設立しました。彼らはSystemRと互換性のあるデータベースの作成を目指しました。1979年にこの会社はRelationalSoftware、Inc(RSI)に改名され、1982年に最終的にOracle SystemsCorporationに改名されました。Oracleは今後も最大かつ最も収益性の高いデータベースベンダーになります。世界。彼らはCプログラミング言語を使用してソフトウェアを開発しました。これは、高性能であり、Cをサポートする任意のプラットフォームに移植できることを意味します。 1980年代までに、市場での競争は激化したが、オラクルは引き続き企業を支配していた。80年代の終わりに向けて、MicrosoftはSQL Server1.0と呼ばれるOS / 2プラットフォーム用のデータベースを開発しました。1993年に、これをWindows NTプラットフォームに移植し、当時のWindowsテクノロジの採用により、中小企業の標準となりました。マイクロソフトが90年代半ばから後半に作成した開発環境(Visual Basic、次に.NET)は、長年の経験を積んだ開発者だけでなく、誰でもアプリケーションでデータベースの力を利用できることを意味しました。1998年までに、彼らはSQL Server V7をリリースし、製品は市場でより確立されたプレーヤーと競争するのに十分成熟しました。
90年代初頭には、少なくともオンライン市場では、他のどのデータベースよりも大きな影響を与える別のデータベースが作成されました。1990年代半ばには、ソフトウェア開発に革命が起こりました。それは、90年代にほとんどのPCシステムで使用されていたコードのマイクロソフトの支配と厳格な管理に対抗するために起こり、オープンソース運動が生まれました。彼らはプロプライエタリの商用ソフトウェアを信じず、代わりに無料で配布可能なソフトウェアを開発しました(そしてコードを公開しました)。1995年に、MySQLの最初のバージョンがスウェーデンの会社(オープンソースプロジェクトに資金を提供した)によってリリースされました— MySQLAB。このソフトウェアはインターネットの最初の重要なデータベースであり、Google(検索用ではありませんが)、Facebook、Twitter、Flickr、Youtubeなどの企業で引き続き使用されています。オープンソースライセンスは、Webサイト開発者に自由を与え、OracleやMicrosoftなどの企業に依存する必要がないことを意味しました。また、今日使用しているインターネットの基盤を作成した他のオープンソースソフトウェアともうまく機能しました(Linux、Apache、MySQL、PHP(LAMP)がWebサイトの最も一般的なセットアップになりました)。MySQL AB(MySQLプロジェクトを後援した会社)は最終的にSun Microsystemsに買収され、その後Oracleに買収されました。 その後数年で、他の多くのオープンソースデータベースが作成されました。OracleがMySQLを買収したとき、MySQLプロジェクトの創設者はプロジェクトのフォークを作成しました(つまり、彼はコードを取得して、別の名前で新しいプロジェクトを開始しました)。この新しいプロジェクトはMariaDBと呼ばれていました。現在、さまざまなライセンスとイデオロギーを持つ多数のオープンソースデータベースがあります。
2000年以降とNoSQL
この記事のこれまでのところ、言及されているすべてのデータベースは、データベースにデータを取得して格納するための主な方法として構造化照会言語(SQL)を使用しています。1998年に、新しい用語、つまりNoSQLが作成されました。これは、他のクエリ言語を使用してデータを格納および取得する「SQLだけでなく」データベースを指します。これらのタイプのデータベースは1960年代から存在していましたが、テクノロジーの世界で注目を集めたのはWeb2.0革命でした。 Web 1.0は、ユーザーがWebマスターとそのチームによって作成されたコンテンツを受信して取り込んだときのインターネットの最初の反復でした。Web 2.0は、ユーザー生成コンテンツへの移行であり、すべての人にとってよりユーザーフレンドリーなインターネットでした。Youtubeやソーシャルメディアのようなサイトは、インターネットのこの段階を象徴しています。データベースの場合、それは開発者と管理者のニーズが変化したことを意味しました。ユーザーによって毎秒膨大な量のデータがインターネットに追加されていました。クラウドコンピューティングは、大規模なストレージと処理機能のロックを解除し、データベースの使用方法が変化しました。 このテクノロジーの時代では、新しいインターネットの性質が大幅に拡大しているため、要件は設計とスケーラビリティに関する単純さへとシフトしました。また、24時間年中無休の可用性と速度が最も重要になったことが不可欠でした。従来のリレーショナルデータベースは、特に必要なスケーラビリティと速度に苦労し、NoSQLがさまざまなデータ構造(つまり、キー値、グラフ、ドキュメント)を使用しているため、一般的に高速でした。また、従来のリレーショナルデータベースと同じ制約がなかったため、より柔軟であると見なされていました。 NoSQLにはいくつかの欠点がありました。特に、テーブル間で結合を使用できず、標準化されていませんでした。ただし、新世代のWeb開発者にとっては、NoSQLの方が優れていました。これは、21世紀の最初の20年間に行われた大規模なイノベーションの主な理由のひとつでした。これは、ウェブサイト(およびその後のアプリ)の開発がはるかに簡単になり、ワールドワイドウェブの成長する性質に対処できるためです。リレーショナルデータベースは、オンラインの世界でそれらから離れたにもかかわらず、その地位を維持し続けました。企業は、ビジネスシステムのプログラミングの信頼性、一貫性、および容易さを依然として必要としていました。
データベースの種類
コンピュータ技術の発展はいつも資本主義のプラットフォーム上で行われてきました。つまり、ビジネスになるものは技術発展したし、お金にならない研究はだんだんと収束していきます。実際に様々なデータベースの種類がありましたが、その中でもRDBが栄えたのはビジネスロジックに組み込みやすかったからです。 これからもビジネスに組み込める形のデータベースは多くの企業で使用されていくと思いますが、その点RDBは現実世界をそのまま表現できるためRDBは数十年の単位では消えないと思っています。
ここでは企業に使われるようになっているデータベースの種類を紹介したいと思います。
- RDB
- NoSQL
- ドキュメント指向型
- キー・バリュー型
- グラフ型
- カラム指向型
- NewSQL
RDB
データベースの歴史もかなり早い段階から出てきましたが、シェア率も80%を超えています。(DB-Engines Rankingより)現実世界で生活している人にとって理解しやすいモデルだと思うので、詳細な説明は省きます。なにかしらのおすすめだと言われている本を一冊読み込むのがいいでしょう。
一番一般的ではありますが、もちろんRDBにも欠点があります。RDBは書き込みの大量リクエストに弱いです。その課題を解決しようということで次のNoSQLが開発されました。
NoSQL
NoSQLは「SQLではない」ではなく、Not only SQLで「SQLだけではない」という意味です。つまり、RDBではないSQLの総称として呼ばれているのでNoSQLだけでも種類が豊富で理解に少し時間がかかると思います。
種類が多いのでデータモデルとアーキテクチャの観点で分類すると参考記事にもある通りこのように分類することができます。
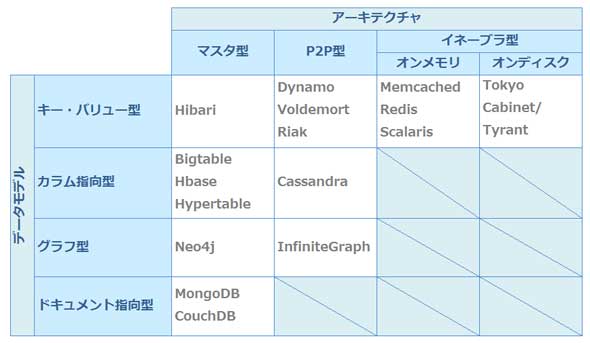
出典:KVS系NoSQLのまとめ(Hibari、Dynamo、Voldemort、Riak編)
ドキュメント指向型
ドキュメント指向のNoSQLデータベース(CouchDB、MongoDB)編 開発者が知っておくべき、ドキュメント・データベースの基礎
ドキュメント指向型は、パフォーマンス、大量データ、スケーラブルといった課題を克服するためのシンプルなセットを提供しており、JSONやXMLのような構造であるドキュメントにさまざまな型のオブジェクトをそのまま登録できるというRDBとは異なる特徴を持っています。
キー・バリュー型
KVS系NoSQLのまとめ(Hibari、Dynamo、Voldemort、Riak編)
キー・バリュー型のデータモデルは、キーとバリューの組み合わせでデータを書き込み、キーによりバリューを読み出すというシンプルな構造です。ただし、そのアーキテクチャは複数あり、大きく分けてマスタ型とP2P型があります。アーキテクチャはこのいずれかなのですが、ここではあえて、第3の分類としてイネーブラ型という類型を設け、その特徴を明らかにします。
イネーブラ型のNoSQLデータベースは、単体でも利用できます。実際に単体で利用されるケースが多いのですが、他のデータベースと組み合わせたときに、特段の利用効果を発揮するという特性を持ったソフトウェアです。「他のデータベース」とは、SQLデータベース、永続性を提供するNoSQLデータベース、拡張性を提供するNoSQLデータベースのことです。
イネーブラ型はさらに、「オンメモリ」タイプと「オンディスク」タイプに分けられます。オンメモリタイプはデータの永続性を保証しません。メモリ上で動作するので、性能面では高速処理ができるものの、サーバの電源を切ってしまえばデータが消失してしまいます。一方、オンディスクタイプは、データをハードディスクに書き込むことでデータの永続性を保証するものの、複数のサーバにデータベースを分割して保有するという拡張性を有しません。
グラフ型
グラフ型NoSQLデータベース(Neo4j、InfiniteGraph)編 グラフデータベースはどんな用途に向いている?
グラフデータベースとは、「ノード」「リレーション」「プロパティ」の3要素によってノード間の「関係性」を表現する「グラフ型のデータモデル」を持つデータベースといえます。
リレーショナルデータベースではないため「NoSQL」に分類されますが、この「グラフ型のデータモデル」とは、NoSQLといったときに一般的に想起される「KVS(キーバリューストア)型データベース」や「MongoDB」のような「ドキュメント指向データベース」とは異なるデータモデルとなります。
Facebookの知り合いかも機能や複雑なデータの探索に有効的です。グラフ理論のグラフですね。
カラム指向型
カラム指向型データベース(HBase、Hypertable、Cassandra)編
RDBは行指向のデータベースであり、1つ1つの行をひとかたまりのデータとして扱います。それに対して、カラム型データベースは列方向にデータを扱います。そのため、特定の列の値をまとめて処理することに非常に長けています。列単位での大量集計、大量更新が得意で、逆に特定の行を抜き出して更新したり削除したりするのは苦手です。
HBaseとHypertableはGoogleのBig-tableに触発されたマスタ型であり、CassandraはBigtableとAmazon Dynamoのハイブリッドとして開発され、P2P型に分類されます。
NewSQL
最近話題になりやすいNewSQLについてです。 NewSQLは名の通り一番新しいデータベースでRDBとNoSQLのいいとこ取りをしたような設計になっています。RDBのSQLとNoSQLの性能を同時に採用しました。RDBの性能改善としてSQLを崩した状態でNoSQLを開発し、結局SQL使いとのことでNewSQLの需要が生まれました。
有名どころはGoogle Cloud SpannerやCockroachDBなどがあります。 ちなみにCockroachDBはRDB要素があるのでPostgresQLと互換性があります。
データベースの種類まとめ

SQLについて
もしあなたが
select, create, insert, dropしか使えない
という状況でしたらぜひ一度SQLを体系的に学んでみることをおすすめします。SQLの万能さに驚くと思います。通常のCRUDアプリくらいならCRUDレベルのSQLしか使わないですが、もっといろんな事ができます。僕は以前う受けていた案件で「〇〇したときの〇〇な〇〇のユーザーの情報を取得するSQL作っといて」と複雑な条件が絡んだ課題を課せられたときにSQL力が伸びました。
CRUDしか使っていないならJOINから始めて条件文の作り方やGROUP BY、TRANSACTIONなどを学んでいくといいと思います。SQLを自分で作れることでWebサービスをより効率的に開発することができます。普段RailsやLaravelなどの高機能フレームワークを使用する場合はORM(オブジェクトリレーショナルマッパー)というありがたい存在によってあまり気にしないですが、普段書いているコードは結局はORMでSQLに変換されています。
例えばRailsの場合
User.where(city: 'Tokyo') # SELECT "users".* FROM "users" WHERE "users"."city" = ? [["city", "Tokyo"]] # 簡略化すると # SELECT * FROM users WHERE city = "TOKYO"
のようなSQLが発行されます。これをわかってみるとコード上きれいに見えても発行されているSQLを見るとものすごく効率が悪いという場合があったりします。SQLを学ぶメリットとしてSQLを意識したプログラミングができるようになると思います。
ORMについて
ORMについてActive Recordがかなり優秀だと思いますので、Active RecordのWikiを見るとかなり勉強になると思います。今更意識しないですが、中身でどう動いてるのか学ぶことには意味があると思います。もっと実感したいならORMなしで開発してみるのもいいかもしれないですね。 Active Record
設計について
良い設計というのは時と場合によるものです。しかし、悪い設計というものはいかなる状況においても許されるものではありません。であれば悪い設計、つまりアンチパターンを覚えることがキーになってきます。 アンチパターンといばこの本です。みな一度は読んでいるんじゃないでしょうか。
スケーラビリティとは?
システム開発におけるスケールとはシステムキャパシティを広げるという意味で用いられます。スケーラビリティはシステムの拡張性、拡張可能性という意味です。
スケール方法については「垂直」「水平」のどちらかの方向にスケールする2種類があります。
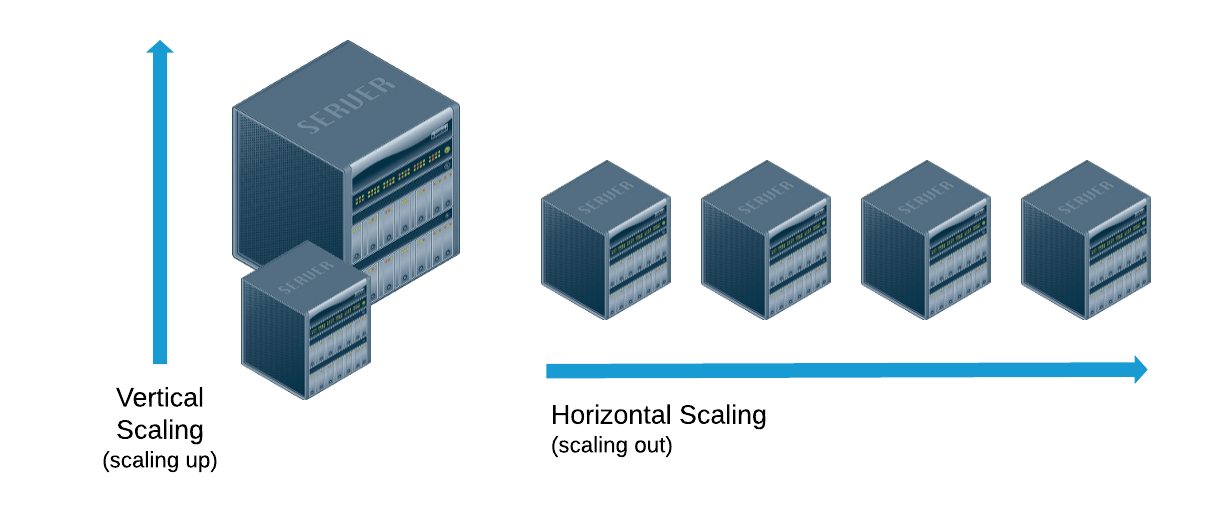
出典:Scaling Horizontally vs. Scaling Vertically
垂直方向のスケール
既存のマシンのCPU、RAMの性能を向上させることにより、キャパシティを広げます。最近のIaasだとボタン一つでスケールアップすることができます。
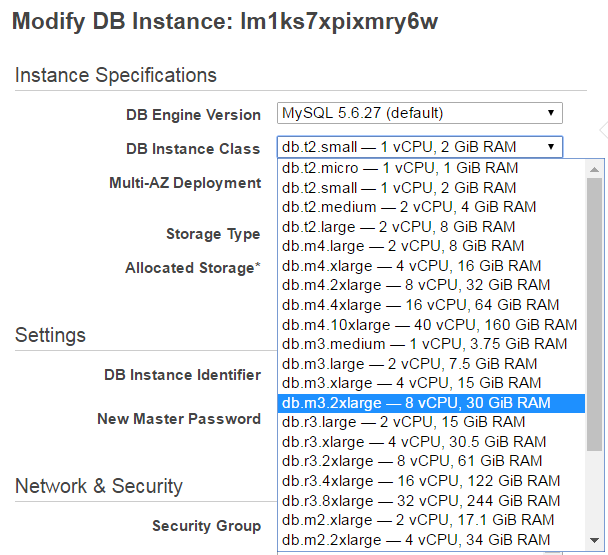
出典:Scaling Your Amazon RDS Instance Vertically and Horizontally
RDBをスケールする際は垂直スケーリングが多いです。また、何気なく使っていましたが、垂直方向にスケールすることをスケールアップ、スペックを下げることをスケールダウンといいます。垂直スケーリングは1台のマシンの容量に制限され、その容量を超えてスケーリングするとダウンタイムが発生する可能性があり、ハードウェアの上限、つまり現在実行しているハードウェアのスケールがあります。
水平方向のスケール
サーバの台数を増やすことにより、キャパシティを広げます。水平方向にスケールすることをスケールアウト、サーバ台数を減らすことをスケールインといいます。理論的には、既存のプールにマシンを追加すると、単一ユニットの容量に制限されず、より少ないダウンタイムで拡張できるようになります。
NoSQLは水平スケーリングがしやすい設計になっています。逆に言うとRDBを水平スケーリングする場合は高度な技術が必要になります。いいとこ取りのNewSQLはリレーションを持ちながらも水平スケーリングも可能な設計になっています。
スケールアウトのアプローチはいくつかあります。
シャーディング(水平分割)
シャーディングは、大量のデータを複数のデータベースに分割することで負荷を分散する手法です。スケールしたアプリケーションサーバからの同時接続数が限界であったり、巨大なデータを扱う際にbufferが溢れDisk/IOが発生する際にこの手法で対処することが多いです。
レプリケーション
レプリケーションとはハードウェアを含め同じシステム環境が2セット(稼働系と待機系)用意された環境において リアルタイムにデータ複製する技術です。万が一、稼働系に障害が発生した時にも、待機系に切り替えるだけで業務を継続することができます。スケールアウトアプローチの中でも実装が一番容易です。
バックアップと何が違うのと思いますが、バックアップはある時点(静止点)のファイルやアプリケーション、およびそれらを含むシステム全体を別の場所に保存する事です。レプリケーションはより動的でバックアップはより静的です。
最後に
思ったよりも豊富な情報量になってしまいましたが、ここで得てほしいのは単語です。なるべく初心者にわかりにくいようなボキャブラリーを選択しました。この記事で説明するようなことはあえてせず、この記事を読むことでわからない単語を知って調べて見るところから始め、この記事で言っていることがだいたい理解できるようになったら一人前のエンジニアです。
正直まだぼくも「データベース得意です!」と言えるほど自身はありません。この世の中にはデータベースエンジニアなる人達がいます。CockroachDBで働いている人の技術記事やDB Weeklyを購読して読むとさらに込み入った話が出てきます。
今年初の記事ですので、今年もどうぞよろしくお願いいたします。
Dockerハンドブック

Dockerの概念や仕組みまではなんとなく理解できるもののDockerfileを書こうとするとスムーズに書けなかったり、そもそものDockerの基礎、あるいはコンテナ技術というものの基礎が抜け落ちていてDocker環境に移行できていないところも多いのではと思い、この記事を翻訳しました。
Source:The Docker Handbook by Farhan Hasin Chowdhury(@Twitter)
本記事は、原著者の許諾のもとに翻訳・掲載しております。
コンテナ化の概念自体はかなり古いですが、2013年にDocker Engineが登場したことで、アプリケーションのコンテナ化がはるかに簡単になりました。
Stack Overflow Developer Survey-2020によると、 Dockerは#1 最も望まれるプラットフォーム、#2 最も愛されるプラットフォーム、および#3 最も人気のあるプラットフォームとなりました。
必要に応じて、最初に始めるときは少し不安があるかもしれません。したがって、この記事では、コンテナ化の基本レベルから中級レベルまでのすべてを学習します。記事全体を読み終えると、次のことができるようになります。
- (ほぼ)すべてのアプリケーションのコンテナ化
- Docker HubにカスタムDockerイメージをアップロードする
- Docker Composeを使用して複数のコンテナを操作する
前提条件
- Linuxターミナルの知識
- JavaScriptの知識(続くプロジェクトの一部はJavaScriptを使用)
プロジェクトコード
サンプルプロジェクトのコードは、次のリポジトリにあります。
https://github.com/fhsinchy/docker-handbook-projects
コードの完成形はcontainerizedブランチにあります。
目次
- コンテナ化とDockerの概要
- Dockerのインストール
- DockerでのHello World
- コンテナの操作
- コンテナ分離のデモ
- カスタムイメージの作成
- Docker Composeを使用したマルチコンテナアプリケーションの操作
- まとめ
コンテナ化とDockerの概要
コンテナ化とは、ソフトウェアコードとそのすべての依存関係を単一のパッケージ内にカプセル化して、どこでも一貫して実行できるようにするプロセスです。
Dockerはオープンソースのコンテナ化プラットフォームです。コンテナと呼ばれる隔離された環境でアプリケーションを実行する機能を提供します。
コンテナは、ハイパーバイザーを必要とせずにホストオペレーティングシステムのカーネルで直接実行できる非常に軽量な仮想マシンのようなものです。その結果、複数のコンテナを同時に実行できます。

各コンテナには、アプリケーションとその依存関係のすべてが含まれており、他の依存関係から分離されています。開発者は、これらのコンテナをレジストリを通じてイメージとして交換でき、サーバーに直接デプロイすることもできます。
仮想マシンとコンテナ
仮想マシンは、仮想CPU、メモリ、ストレージ、およびオペレーティングシステムを備えた物理コンピューターシステムと同じようなエミュレートされたものです。
ハイパーバイザーと呼ばれるプログラムは、仮想マシンを作成して実行します。ハイパーバイザーが実行されている物理コンピューターはホストシステムと呼ばれ、仮想マシンはゲストシステムと呼ばれます。
{kind=link}
ハイパーバイザーはCPU、メモリ、およびストレージのようなリソースを簡単に既存のゲスト仮想マシン間で再割り当てすることができるプールとして扱います。
ハイパーバイザーには次の2つのタイプがあります。
- Type 1(「ネイティブ」または「ベアメタル」)ハイパーバイザ(VMware vSphere、KVM、Microsoft Hyper-V)
- Type 2(「ホスト」)ハイパーバイザ(Oracle VM VirtualBox、VMware Workstation Pro/VMware Fusion)
コンテナは、コードと依存関係を一緒にパッケージ化するアプリケーション層の抽象概念です。物理マシン全体を仮想化する代わりに、コンテナはホストオペレーティングシステムのみを仮想化します。

コンテナは、物理マシンとそのオペレーティングシステムの上に配置されます。各コンテナは、ホストオペレーティングシステムのカーネルと、通常はバイナリとライブラリも共有します。
Dockerのインストール
Docker Desktopのダウンロードページに移動し、ドロップダウンからオペレーティングシステムを選択します。
Macバージョンのインストールプロセスを示しますが、他のオペレーティングシステムへのインストールも同じように簡単なはずです。
Macのインストールプロセスには2つのステップがあります。
- ダウンロードしたDocker.dmgファイルをマウントします。
- DockerをApplicationディレクトリにドラッグアンドドロップします。
次に、アプリケーションディレクトリに移動し、ダブルクリックしてDockerを開きます。daemonが実行され、メニューバー(ウィンドウのタスクバー)にアイコンが表示されます。
このアイコンからDockerダッシュボードにアクセスできます。
現時点では少し退屈に見えるかもしれませんが、いくつかのコンテナを実行すると、これはより興味深いものになります。
DockerでのHello World
Dockerをマシンで実行する準備ができたので、次は最初のコンテナを実行します。ターミナル(Windowsのコマンドプロンプト)を開き、次のコマンドを実行します。
docker run hello-world
すべてがうまくいくと、次のような出力が表示されます。
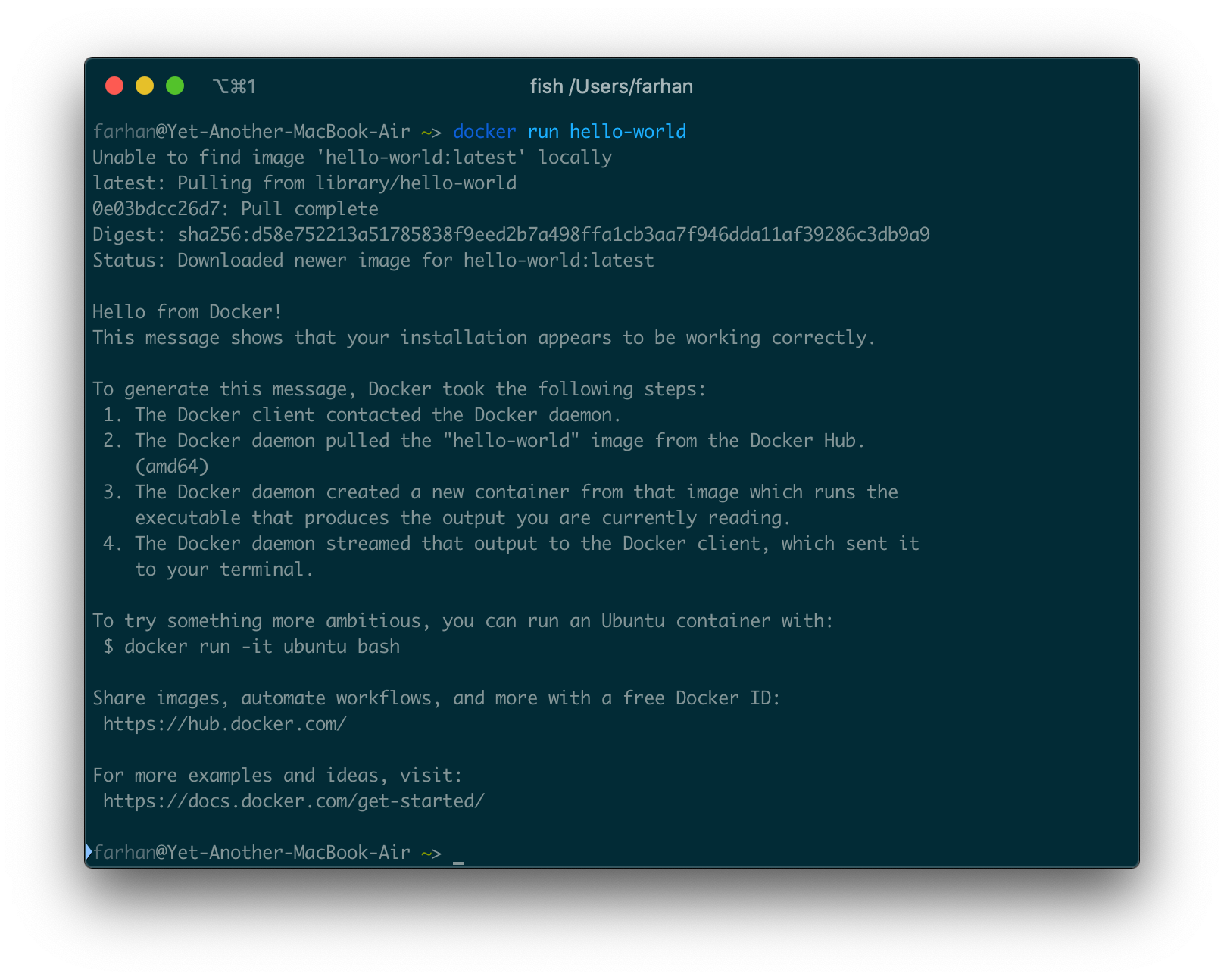
hello-worldイメージは、Dockerでの最小限のコンテナ化の例です。ターミナルに表示されているメッセージを出力するためのhello.cファイルが1つあります。
ほとんどすべてのイメージにはデフォルトのコマンドが含まれています。hello-worldイメージの場合、デフォルトのコマンドは、前述のCコードからコンパイルされたhelloバイナリを実行します。
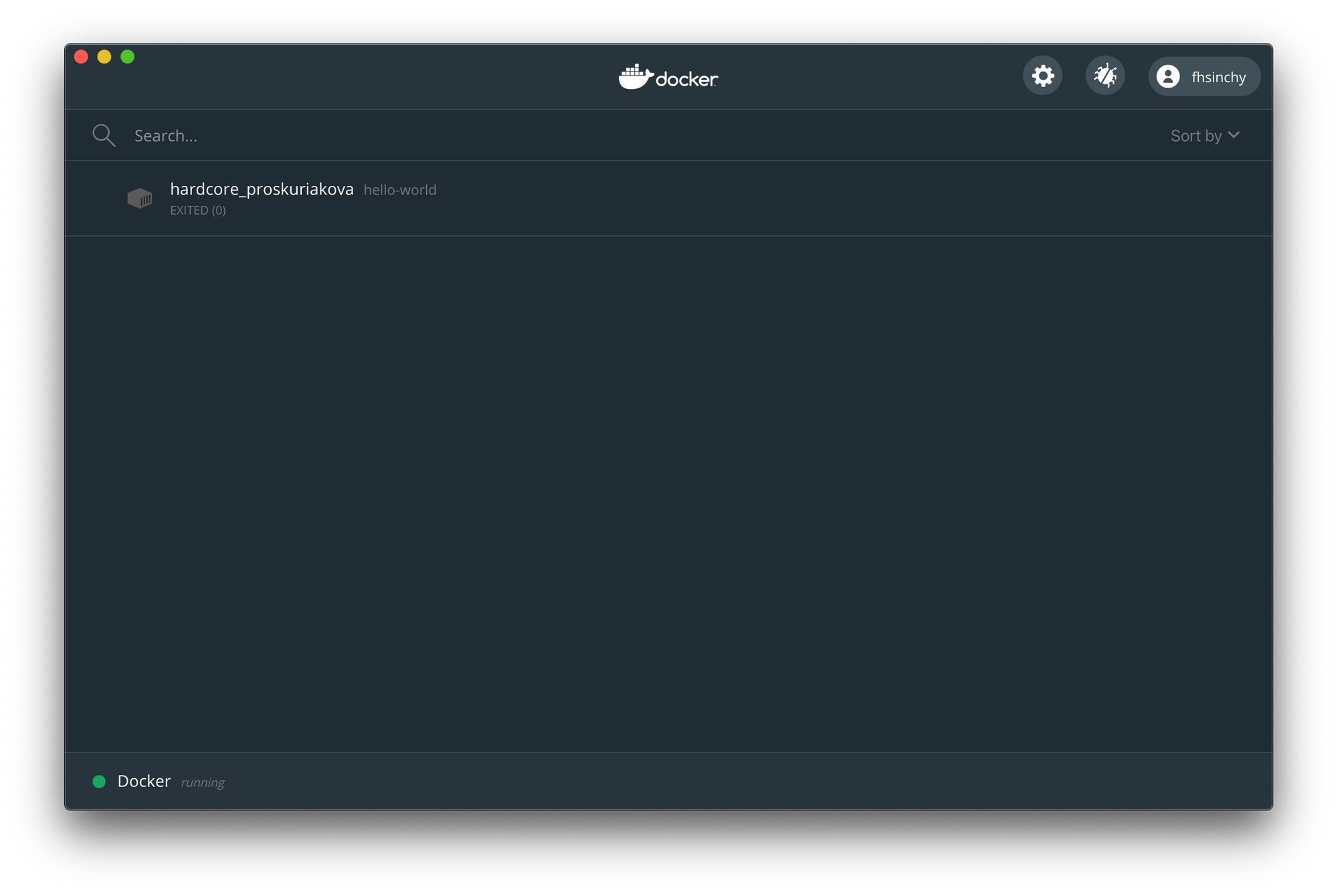
ダッシュボードをもう一度開くと、hello-worldコンテナが表示されています。
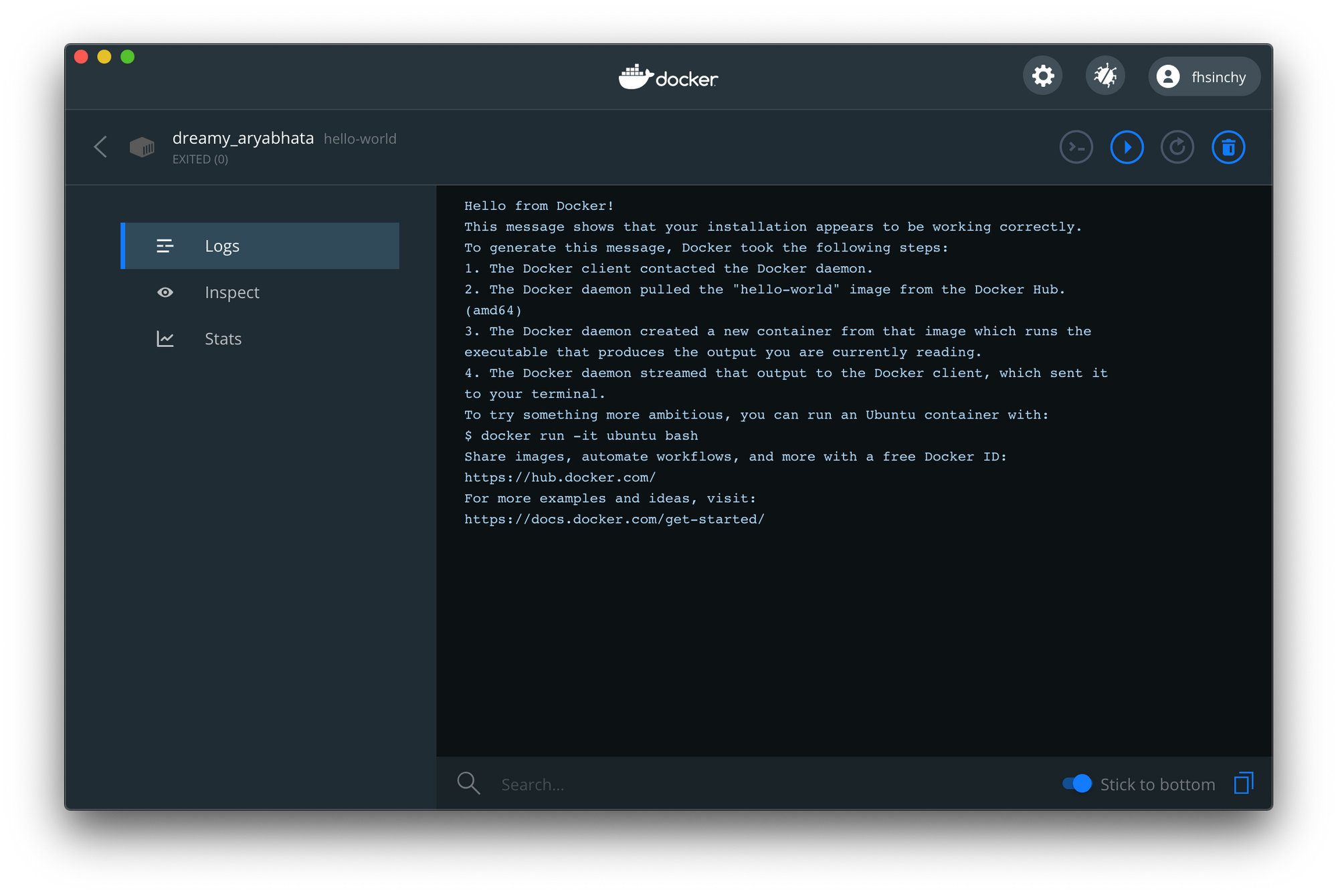
ステータスはEXITED(0)で、コンテナが実行され、正常に終了したことを示しています。Logs 、 Stats(CPU/memory/disk/network usage)またはInspect(environment/port mappings)が確認できます。
何が起こったのかを理解するには、Dockerのアーキテクチャ、イメージとコンテナ、レジストリについて理解する必要があります。
Dockerアーキテクチャ
Dockerはクライアントサーバーアーキテクチャを使用します。エンジンは3つの主要コンポーネントで構成されています。
Dockerデーモン: デーモンは、クライアントが発行したコマンドをリッスンし、バックグラウンドで動作し続ける長時間実行アプリケーションです。イメージ、コンテナ、ネットワーク、ボリュームなどのDockerオブジェクトを管理できます。
Dockerクライアント: クライアントは、
dockerコマンドでアクセスできるCUIプログラムです。このクライアントはサーバーに何をすべきかを伝えます。docker run hello-worldのようなコマンドを実行すると、クライアントはデーモンにタスクを実行するように指示します。REST API: デーモンとクライアント間の通信は、UNIXソケットまたはネットワークインターフェイスを介してREST APIを使用して行われます。
Dockerの公式ドキュメントには、アーキテクチャのわかりやすい図があります。

いま複雑に見えても心配しないでください。次のサブセクションでは、すべてがより明確になります。
イメージとコンテナ
イメージは、コンテナを作成するために必要な指示を含む、多層の自己完結型ファイルです。レジストリを介してイメージを交換できます。他の人が作成したイメージを使用することも、新しい指示を追加して変更することもできます。
scratchからもイメージを作成できます。イメージのベースレイヤーは読み取り専用です。Dockerfileを編集して再構築すると、変更された部分のみが最上位レイヤーに再構築されます。
コンテナは、イメージの実行可能なインスタンスです。hello-worldのようなイメージをプルして実行すると、イメージに含まれているプログラムの実行に適した隔離された環境が作成されます。この隔離された環境がコンテナです。イメージをOOPのクラスと比較すると、コンテナがオブジェクトになります。
レジストリ
レジストリは、Dockerイメージのストレージです。Docker Hubは、イメージを保存するためのデフォルトのパブリックレジストリです。docker runやdocker pullなどのコマンドを実行すると、デーモンは通常ハブからイメージをフェッチします。誰でもdocker pushコマンドを使用してハブに画像をアップロードできます。ハブに移動して、他のWebサイトと同様にイメージを検索できます。
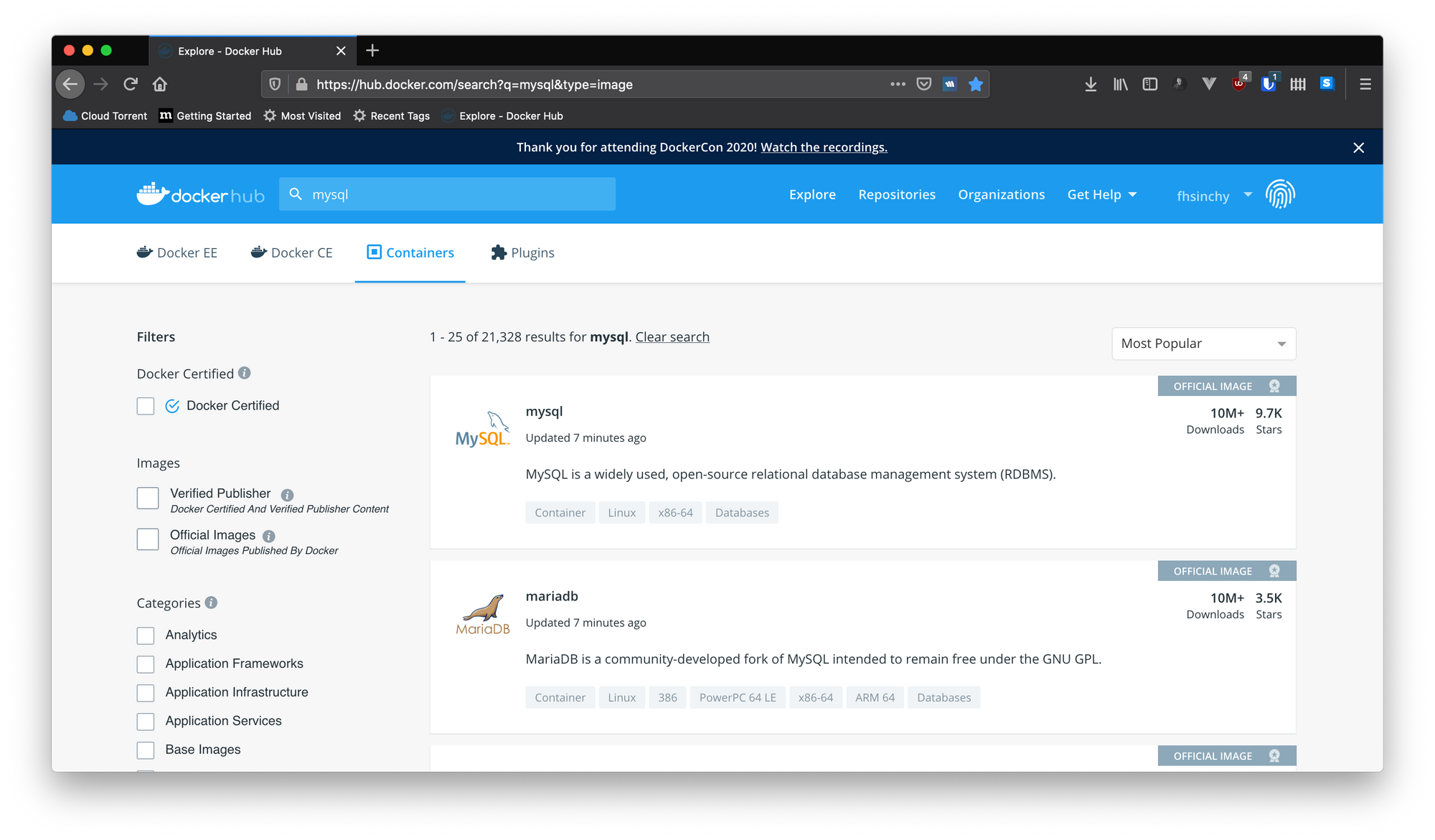
アカウントを作成すると、カスタムイメージもアップロードできるようになります。アップロードした画像は、https://hub.docker.com/u/fhsinchyページで誰でも利用できます。
全体像
アーキテクチャ、イメージ、コンテナ、レジストリに精通したので、docker run hello-worldコマンドを実行したときに何が起こったかを理解する準備が整いました。プロセスの図は次のとおりです。

プロセス全体は5つのステップで行われます。
1.docker run hello-worldコマンドを実行します。
2. Dockerクライアントは、hello-worldイメージを使用してコンテナを実行することをデーモンに通知します。
3. Dockerデーモンは、最新バージョンのイメージをレジストリから取得します。
4. イメージからコンテナを作成します。
5. 新しく作成されたコンテナを実行します。
これは、ローカルに存在しないハブ内のイメージを検索するDockerデーモンのデフォルトの動作です。ただし、イメージがフェッチされると、ローカルキャッシュに残ります。したがって、コマンドを再度実行しても、下記のような出力はされません。
Unable to find image 'hello-world:latest' locally latest: Pulling from library/hello-world 0e03bdcc26d7: Pull complete Digest: sha256:d58e752213a51785838f9eed2b7a498ffa1cb3aa7f946dda11af39286c3db9a9 Status: Downloaded newer image for hello-world:latest
利用可能なイメージの新しいバージョンがある場合、デーモンはイメージを再度フェッチします。その:latestはタグです。イメージには通常、バージョンまたはビルドを示す意味のタグがあります。これについては、後のセクションで詳しく説明します。
コンテナの操作
前のセクションでは、Dockerクライアントについて簡単に触れました。Dockerデーモンにコマンドを渡すのはコマンドラインインターフェースプログラム(CUI)です。このセクションでは、Dockerでのより高度なコンテナ操作について学習します。
コンテナを実行する
前のセクションでは、docker runを使用して、hello-worldイメージを使用するコンテナを作成および実行しました。このコマンドの一般的な構文は次のとおりです。
docker run <イメージ名>
ここでイメージ名は、Docker Hubまたはローカルマシンからの任意のイメージを指定することができます。実行だけでなく、作成し実行と言っていることにお気づきかと思います。その背後にある理由は、docker runコマンドが実際には2つの別個のdockerコマンドの役割を果たしているためです。それが次のとおりです。
1.docker create <イメージ名>- 指定されたイメージからコンテナを作成し、コンテナIDを返します。
2.docker start <コンテナID>- 既に作成されたコンテナの指定されたIDよりコンテナを起動します。
hello-worldイメージからコンテナを作成するには、次のコマンドを実行します。
docker create hello-world
コマンドはこのような長い文字列出力します。cb2d384726da40545d5a203bdb25db1a8c6e6722e5ae03a573d717cd93342f61これがコンテナIDです。このIDは、ビルドされたコンテナを開始するために使用されます。
コンテナを識別するには、コンテナIDの最初の12文字で十分です。文字列全体を使用する代わりに、cb2d384726daを使用するのが適切です。
このコンテナを起動するには、次のコマンドを実行します。
docker start cb2d384726da
コンテナIDを出力として返す必要があります。コンテナが適切に実行されていないと思われるかもしれません。しかし、ダッシュボードを確認すると、コンテナが実行され、正常に終了したことがわかります。
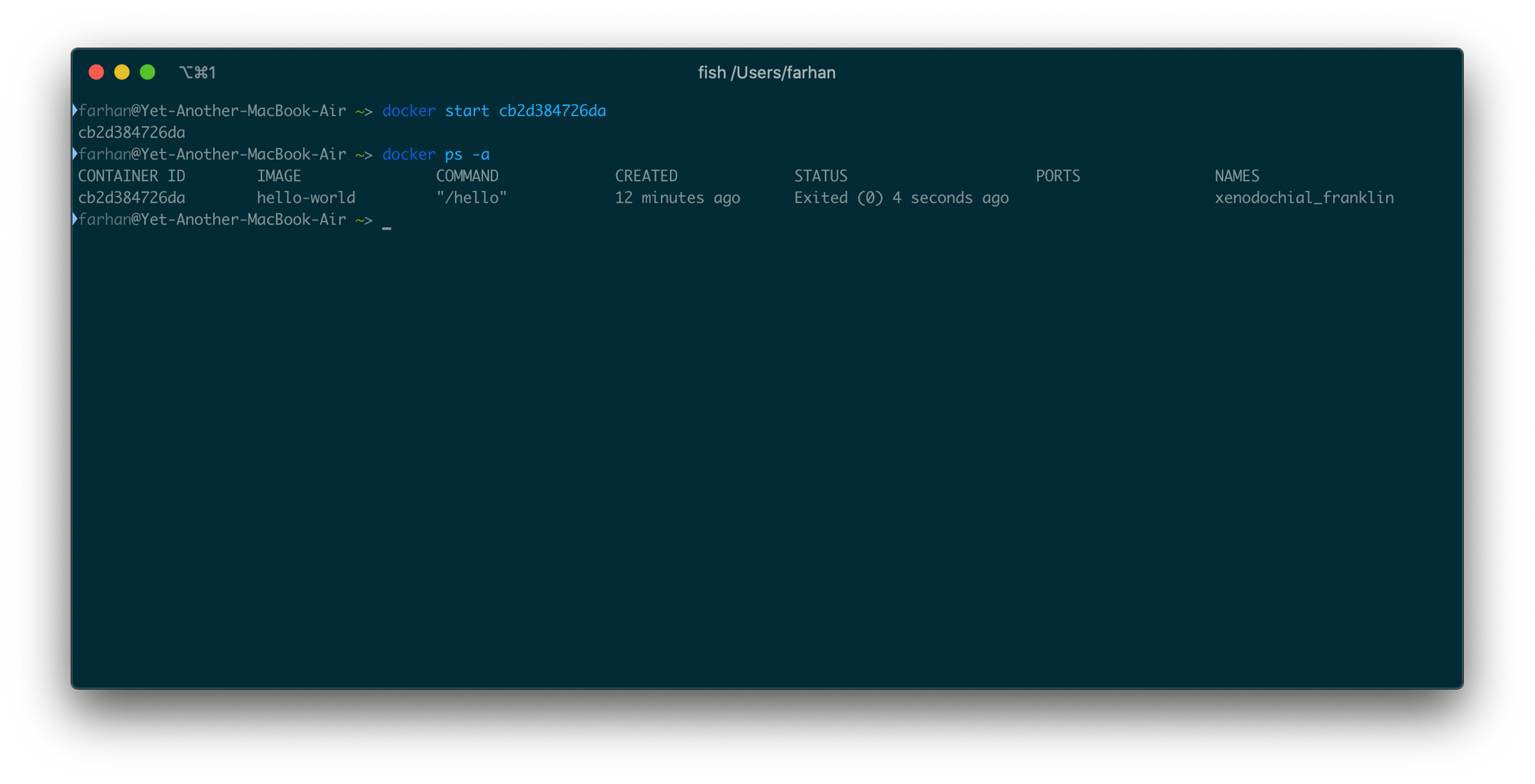
ここで起こったことは、ターミナルをコンテナの出力ストリームに接続しなかったということです。UNIXおよびLINUXコマンドは、通常、実行時に3つのI/Oストリーム、つまりSTDIN、STDOUT、およびSTDERRを開きます。
詳細については、このトピックに関するすばらしい記事があります。
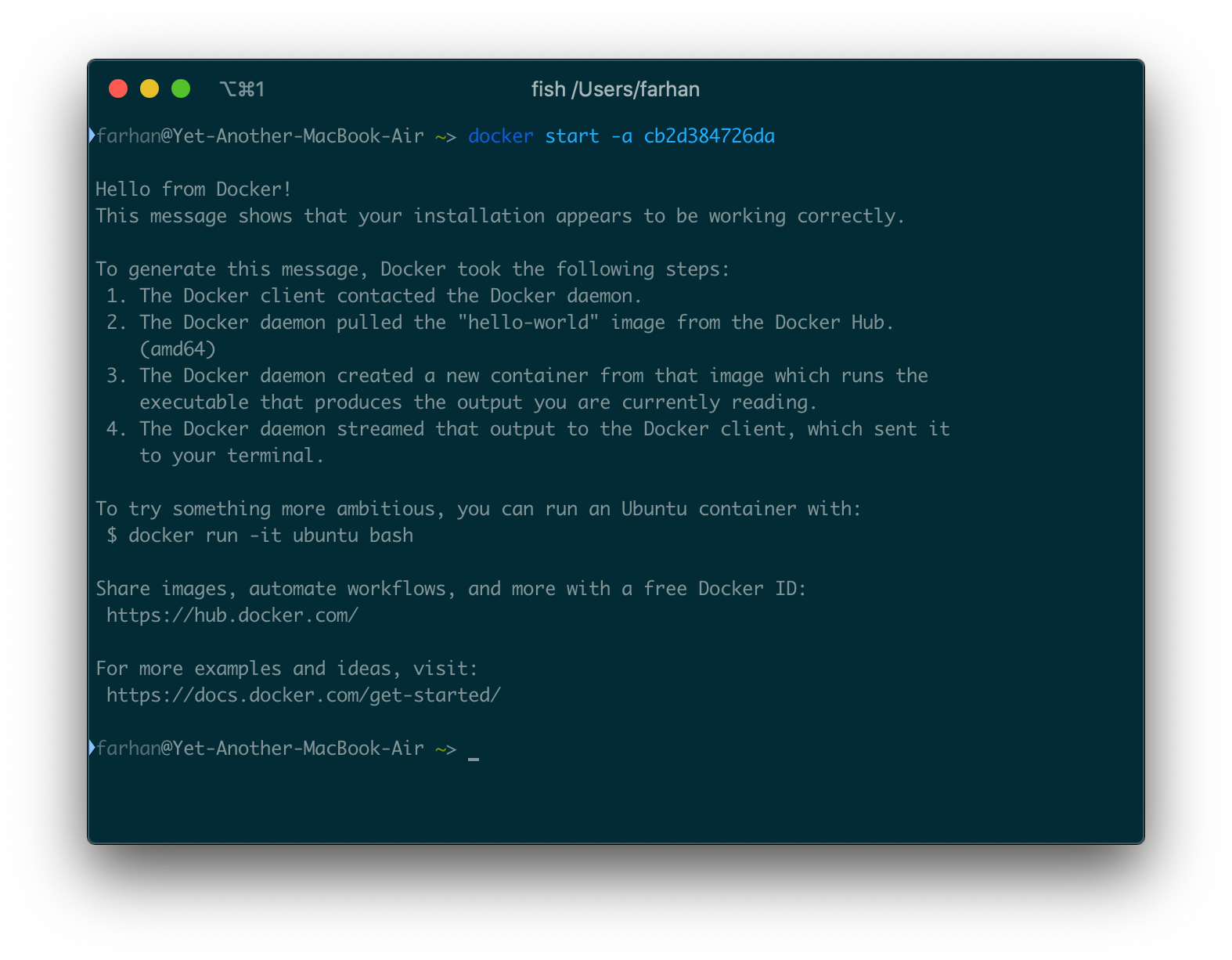
ターミナルをコンテナの出力ストリームに接続するには、-aまたは--attachオプションを使用する必要があります。
docker start -a cb2d384726da
すべてが正常に完了すると、次の出力が表示されます。
startコマンドを使用して、まだ実行されていないコンテナを実行できます。runコマンドを使用すると、毎回新しいコンテナが作成されます。
コンテナの一覧表示
前のセクションで、ダッシュボードを使用してコンテナを簡単に確認できることを覚えているかもしれません。
これは、個々のコンテナを確認するためにはかなり便利なツールですが、コンテナの単純なリストを表示するには多すぎます。これが、より簡単な方法がある理由です。ターミナルで次のコマンドを実行します。
docker ps -a
そして、ターミナル上のすべてのコンテナの一覧が表示されます。
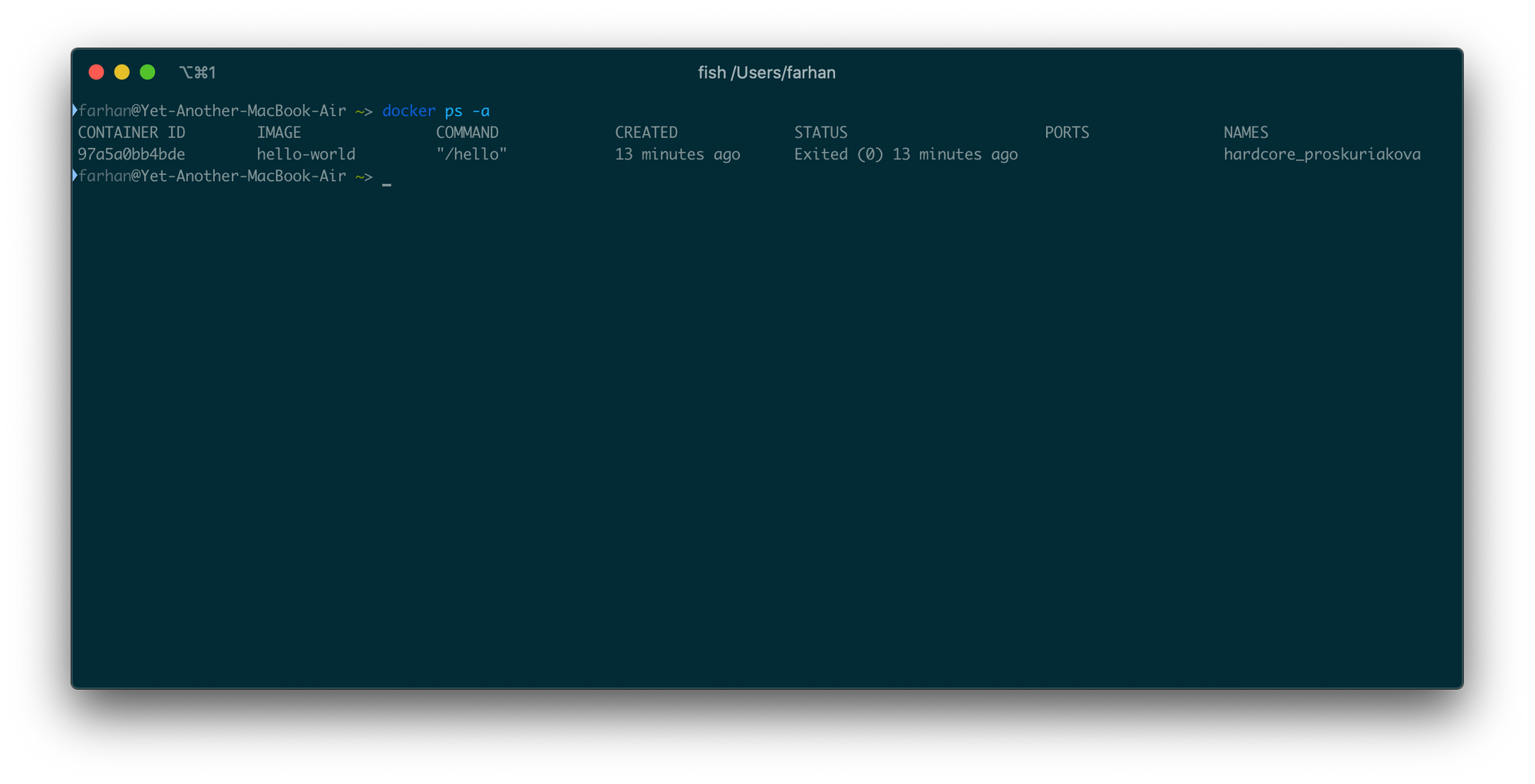
-aまたは--allオプションは、実行中のコンテナだけでなく、停止中のコンテナも表示します。-aオプションなしでpsを実行すると、実行中のコンテナのみが一覧表示されます。
コンテナの再起動
コンテナを実行するためにはstartコマンドを使用しました。restartというコンテナを開始するための別のコマンドがあります。コマンドは表面的には同じ目的を果たしているように見えますが、若干の違いがあります。
startコマンドは実行されていないコンテナを起動します。ただし、restartコマンドは実行中のコンテナを強制終了し、それを再度起動します。停止したコンテナでrestartを使用すると、startコマンドと同じように機能します。
ダングリングコンテナのクリーンアップ
すでに終了したコンテナはシステムに残ります。これらのダングリングまたは不要なコンテナはスペースを占有し、後で問題が発生する可能性さえあります。
コンテナをクリーンアップする方法はいくつかあります。特定のコンテナを削除したい場合は、rmコマンドを使用できます。このコマンドの一般的な構文は次のとおりです。
docker rm <コンテナID>
IDがe210d4695c51のコンテナを削除するには、次のコマンドを実行します。
docker rm e210d4695c51
そして、削除されたコンテナのIDを出力として取得する必要があります。すべてのDockerオブジェクト(イメージ、コンテナ、ネットワーク、ビルドキャッシュ)をクリーンアップする場合は、次のコマンドを使用できます。
docker system prune
Dockerは確認してきます。-fまたは--forceオプションを使用して、この確認手順をスキップできます。このコマンドは、実行が正常に終了したときに削減された容量を表示します。
インタラクティブモードでのコンテナの実行
これまでのところ、hello-worldイメージから構築されたコンテナのみを実行しています。hello-worldイメージのデフォルトのコマンドは、イメージに付属する単一のhello.cプログラムを実行することです。
すべてのイメージはそれほど単純ではありません。イメージは、オペレーティングシステム全体をカプセル化できます。Ubuntu、Fedora、DebianなどのLinuxディストリビューションには、すべてDocker Hubで利用可能な公式のDockerイメージがあります。
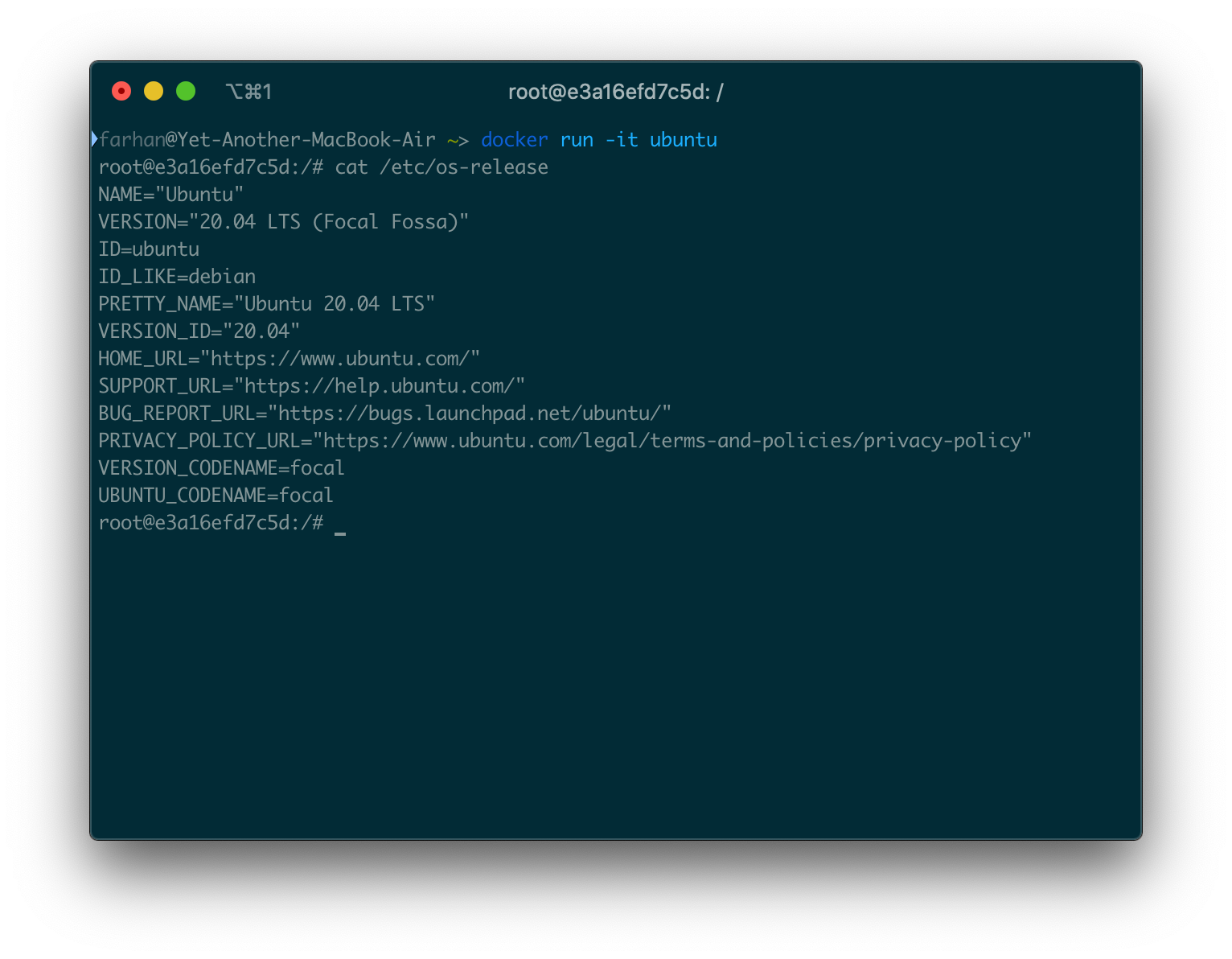
公式のubuntuイメージを使用して、コンテナ内でUbuntuを実行できます。docker run ubuntuコマンドを実行してUbuntuコンテナを実行しようとしても、何も起こりません。ただし、次のように-itオプションを指定してコマンドを実行すると、
docker run -it ubuntu
Ubuntuコンテナ内のbashに直接アクセスする必要があります。このbashウィンドウでは、普段のUbuntuターミナルで実行するようなタスクを実行できます。標準のcat / etc / os-releaseコマンドを実行して、OSの詳細を出力しました。
この-itオプションが必要な理由は、Ubuntuイメージが起動時にbashを開始するように構成されているためです。bashはインタラクティブプログラムです。つまり、何のコマンドも入力しければ、bashは何もしないということです。
コンテナ内のプログラムとやりとりするには、インタラクティブセッションが必要であることをコンテナに明示的に知らせる必要があります。
-itオプションは、コンテナ内のインタラクティブなプログラムとやりとりするための場を設定します。このオプションは、実際には2つの個別のオプションを組み合わせたものです。
*-iオプションはコンテナの入力ストリームに接続するため、入力をbashに送信できます。
*-tオプションは、いくつかの優れたフォーマットとネイティブターミナルのような体験を確実にします。
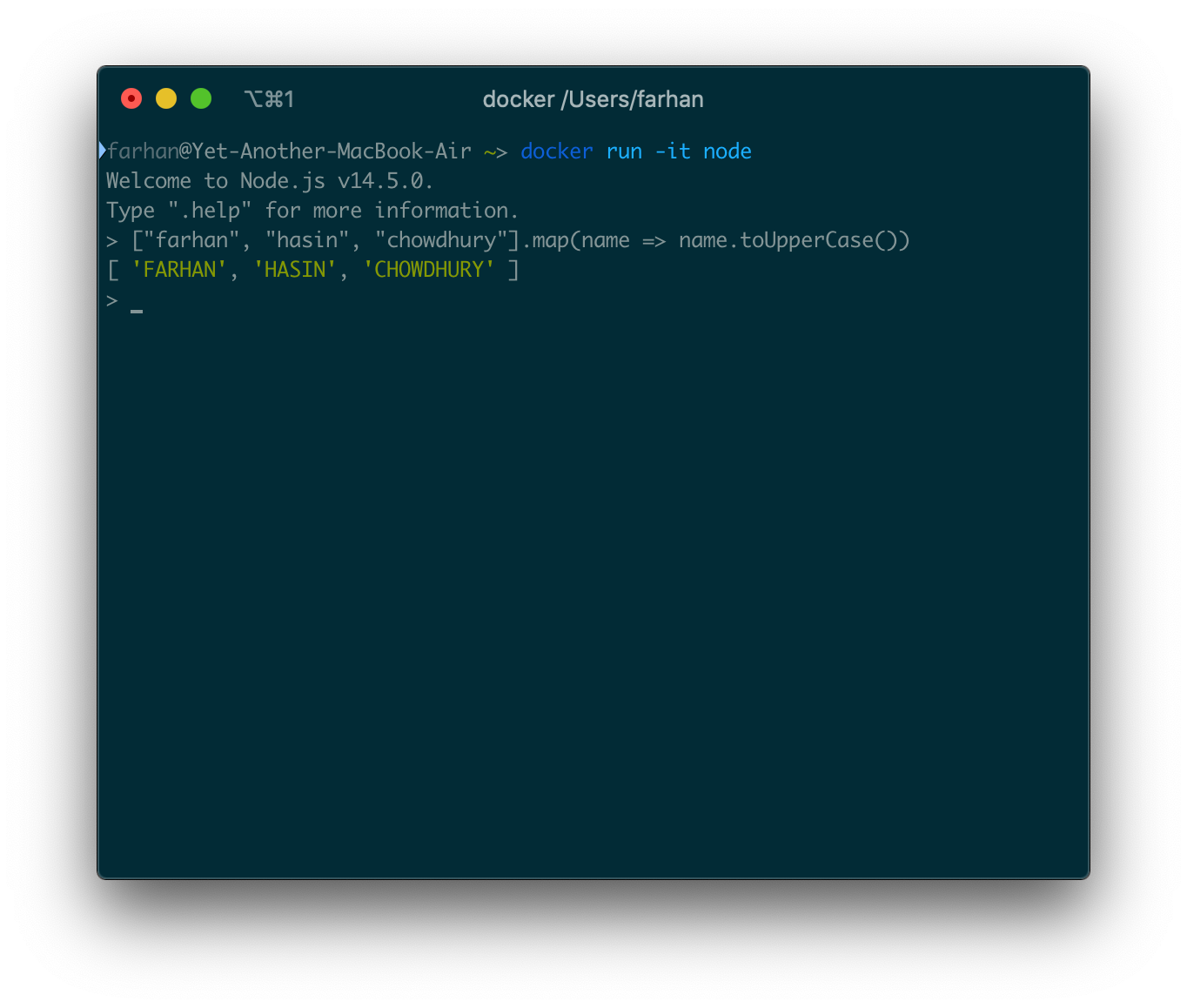
インタラクティブモードでコンテナを実行するときはいつでも、-itオプションを使用する必要があります。docker run -it nodeまたはdocker run -it pythonを実行すると、nodeまたはpythonのREPLプログラムに直接到達するはずです。
インタラクティブモードでランダムにコンテナを実行することはできません。インタラクティブモードで実行できるようにするには、起動時にインタラクティブプログラムを起動するようにコンテナを設定する必要があります。Shell、REPL、CLIなどは、いくつかのインタラクティブプログラムの例です。
実行可能イメージを使用してコンテナを作成する
これまで、Dockerイメージには、自動的に実行されるデフォルトのコマンドがあると言ってきました。すべてのイメージがそうではありません。一部のイメージは、コマンド(CMD)ではなくエントリポイント(ENTRYPOINT)で構成されています。
エントリポイントを使用すると、実行可能ファイルとして実行されるコンテナを構成できます。他の通常の実行可能ファイルと同様に、これらのコンテナに引数を渡すことができます。実行可能コンテナに引数を渡すための一般的な構文は次のとおりです。
docker run <イメージ名> <引数>
Ubuntuイメージは実行可能ファイルであり、イメージのエントリポイントはbashです。実行可能コンテナに渡される引数は、エントリポイントプログラムに直接渡されます。つまり、Ubuntuイメージに渡す引数はすべてbashに直接渡されます。
Ubuntuコンテナ内のすべてのディレクトリのリストを表示するには、lsコマンドを引数として渡します。
docker run ubuntu ls
次のようなディレクトリのリストが表示されます。
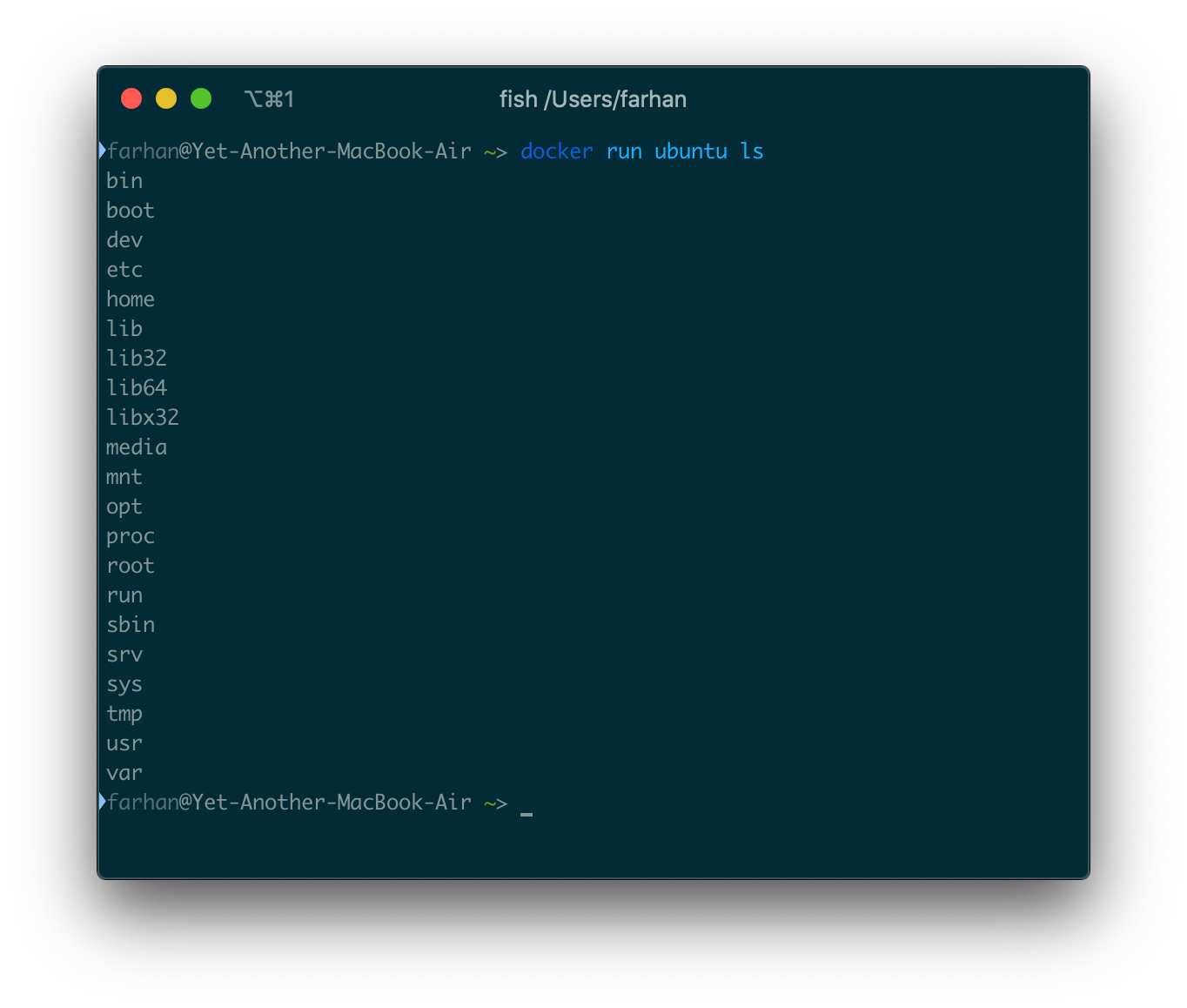
-itオプションを使用していないことに注意してください。bashとやりとりしようとするのではなく、出力が必要なだけだからです。有効なbashコマンドを引数として渡すことができます。pwdコマンドを引数として渡すと、現在の作業ディレクトリが返されます。
有効な引数のリストは通常、エントリポイントプログラム自体によって異なります。コンテナがシェルをエントリーポイントとして使用する場合、任意の有効なシェルコマンドを引数として渡すことができます。コンテナが他のプログラムをエントリーポイントとして使用する場合、その特定のプログラムに有効な引数をコンテナに渡すことができます。
デタッチモードでコンテナを実行する
コンピューターでRedisサーバーを実行するとします。Redisは非常に高速なインメモリデータベースシステムであり、さまざまなアプリケーションでキャッシュとしてよく使用されます。公式のredisイメージを使用してRedisサーバーを実行できます。これを行うには、次のコマンドを実行します。
docker run redis
ハブからイメージを取得するのにしばらく時間がかかる場合があります。その後、ターミナルにテキストの壁が表示されるはずです。
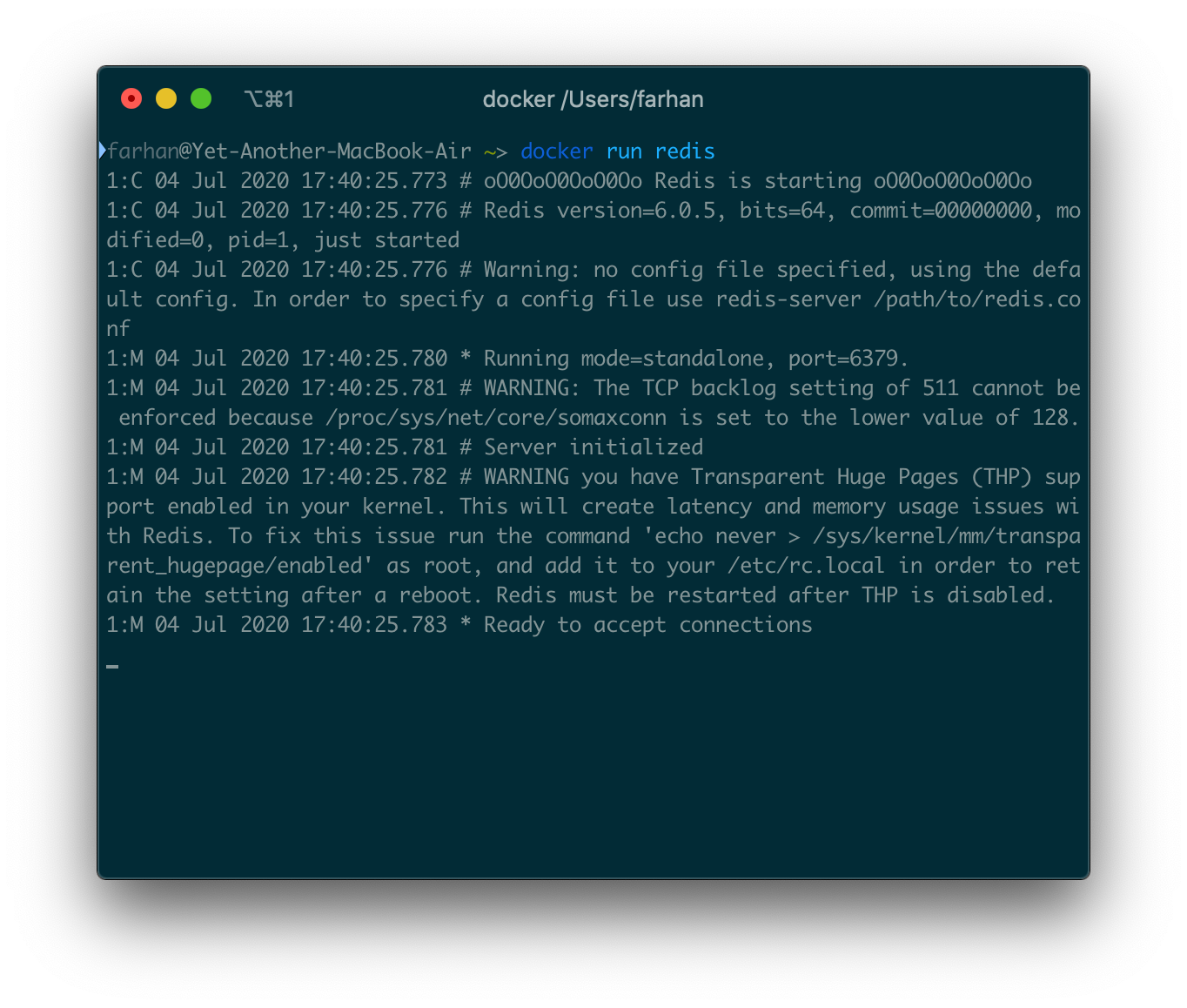
ご覧のとおり、Redisサーバーは実行中であり、接続を受け入れる準備ができています。サーバーを実行し続けるには、このターミナルウィンドウを開いたままにする必要があります(これは私の考えでは面倒です)。
これらの種類のコンテナは、デタッチモードで実行できます。デタッチモードで実行されているコンテナは、サービスのようにバックグラウンドで実行されます。コンテナをデタッチするには、-dまたは--detachオプションを使用できます。コンテナをデタッチモードで実行するには、次のコマンドを実行します。
docker run -d redis
コンテナIDを出力として取得する必要があります。
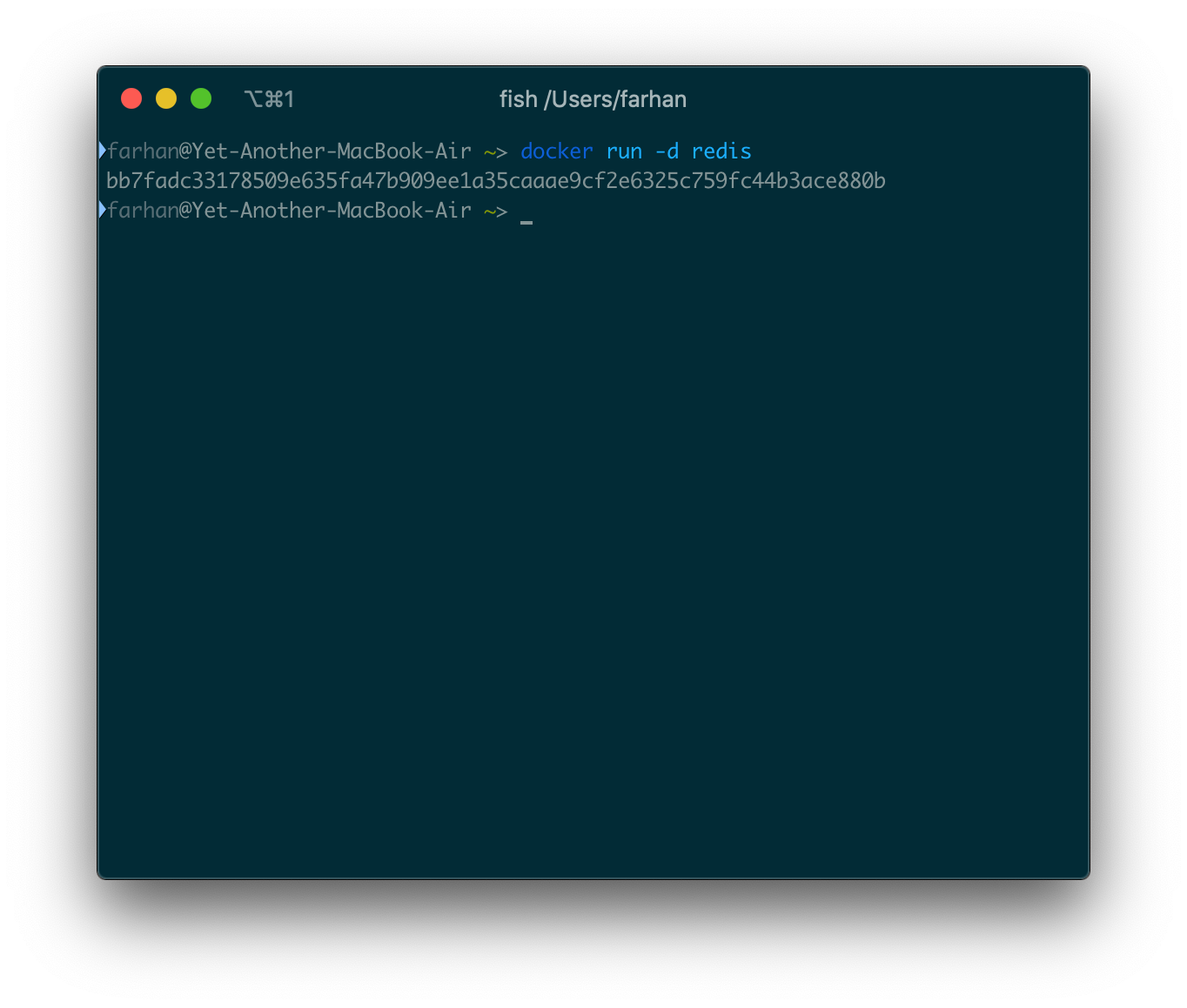
Redisサーバーがバックグラウンドで実行されています。ダッシュボードを使用するか、psコマンドを使用して確認できます。
実行中のコンテナ内でコマンドを実行する
Redisサーバーがバックグラウンドで実行されたので、redis-cliツールを使用していくつかの操作を実行するとします。先に進んでdocker run redis redis-cliを実行することはできません。コンテナは既に実行中です。
このような状況では、実行中のコンテナ内にexecと呼ばれる他のコマンドを実行するコマンドがあり、このコマンドの一般的な構文は次のとおりです。
docker exec <コンテナID> <コマンド>
RedisコンテナのIDが5531133af6a1の場合、コマンドは次のようになります。
docker exec -it 5531133af6a1 redis-cli
そして、redis-cliプログラムに入り込みます。
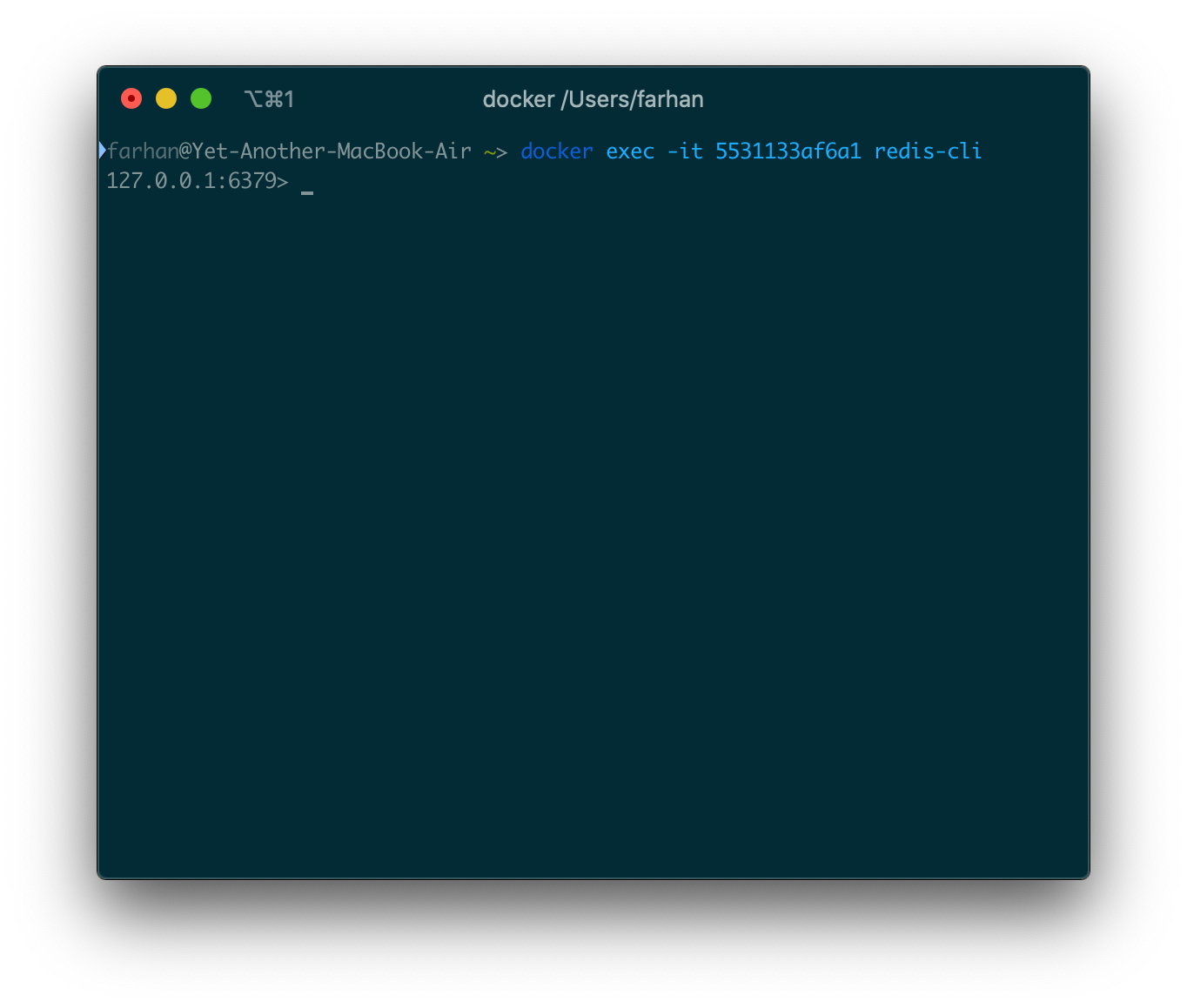
これはインタラクティブセッションになるため、-itオプションを使用していることに注意してください。このウィンドウではどの有効なRedisコマンドでも実行でき、データはサーバーに保持されます。
ctrl + cを押すか、ターミナルウィンドウを閉じるだけで終了できます。ただし、CLIプログラムを終了しても、サーバーはバックグラウンドで実行され続けることに注意してください。
実行中のコンテナ内でシェルを起動する
なんらかの理由で、実行中のコンテナ内でシェルを使用したいとします。これは、次のコマンドのように、 実行可能であるshを添えてexecコマンドを実行してできます。
docker exec -it <コンテナID> sh
redisコンテナのIDが5531133af6a1の場合、次のコマンドを実行してコンテナ内のシェルを起動します。
docker run exec -it 5531133af6a1 sh
コンテナ内のシェルに入れるはずです。
ここで有効なシェルコマンドを実行できます。
実行中のコンテナからログにアクセスする
コンテナからのログを表示する場合は、ダッシュボードが非常に役立ちます。
また、logsコマンドを使用して、実行中のコンテナからログを取得することもできます。コマンドの一般的な構文は次のとおりです。
docker logs <コンテナID>
RedisコンテナのIDが5531133af6a1の場合、次のコマンドを実行してコンテナのログにアクセスします。
docker logs 5531133af6a1
ターミナルウィンドウにテキストの壁が表示されるはずです。
これはログ出力の一部にすぎません。-fまたは--followオプションを使用すれば、コンテナの出力ストリームにフックして、リアルタイムでログを取得できます。
それ以降のログは、ctrl + cを押すかウィンドウを閉じて終了しない限り、即座にターミナルに表示されます。ログウィンドウを終了しても、コンテナは実行を続けます。
実行中のコンテナを停止または強制終了する
ターミナルで実行中のコンテナは、ターミナルウィンドウを閉じるか、ctrl + cを押すだけで停止できます。ただし、バックグラウンドで実行されているコンテナを同じ方法で停止することはできません。
実行中のコンテナを停止するには、2つのコマンドがあります。
*docker stop <コンテナID>-SIGTERMシグナルをコンテナに送信して、コンテナを正常に停止しようとします。コンテナが制限時間内に停止しない場合、SIGKILLシグナルが送信されます。
*docker kill <コンテナID>-SIGKILLシグナルを送信してコンテナを即座に停止します。SIGKILLシグナルを受け取ったら無視することはできません。
IDがbb7fadc33178のコンテナを停止するには、docker stop bb7fadc33178コマンドを実行します。docker kill bb7fadc33178を使用すると、クリーンアップする機会を与えずにコンテナが即座に終了します。
ポートのマッピング
人気のWebサーバーであるNginxのインスタンスを実行するとします。これは、公式のnginxイメージを使用して行うことができます。次のコマンドを実行してコンテナを実行します。
docker run nginx
Nginxは実行し続けることを意図しているため、-dまたは--detachオプションを使用することもできます。デフォルトでは、Nginxはポート80番で実行されます。しかし、http://localhost:80にアクセスしようとすると、次のように表示されます。
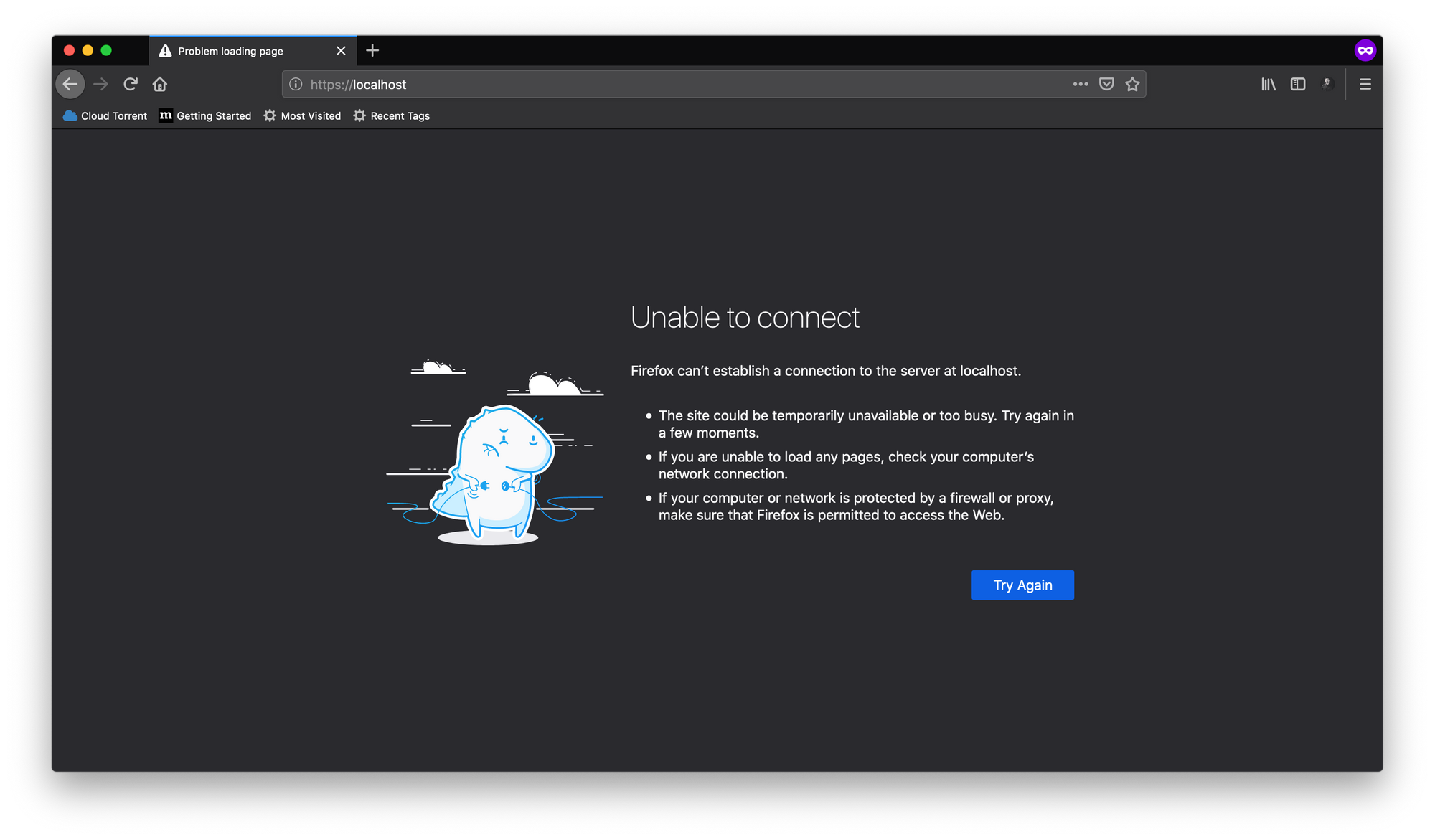
これは、Nginxがコンテナ内のポート80番で実行されているためです。コンテナは分離された環境であり、ホストシステムはコンテナ内で何が行われているのか何も知りません。
コンテナ内のポートにアクセスするには、そのポートをホストシステムのポートにマップする必要があります。これを行うには、docker runコマンドで-pまたは--portオプションを使用します。このオプションの一般的な構文は次のとおりです。
docker run -p <ホストポート:コンテナポート> nginx
docker run -p 80:80 nginxを実行すると、ホストマシンのポート80番がコンテナのポート80番にマッピングされます。次に、http://localhost:80アドレスにアクセスしてみます。
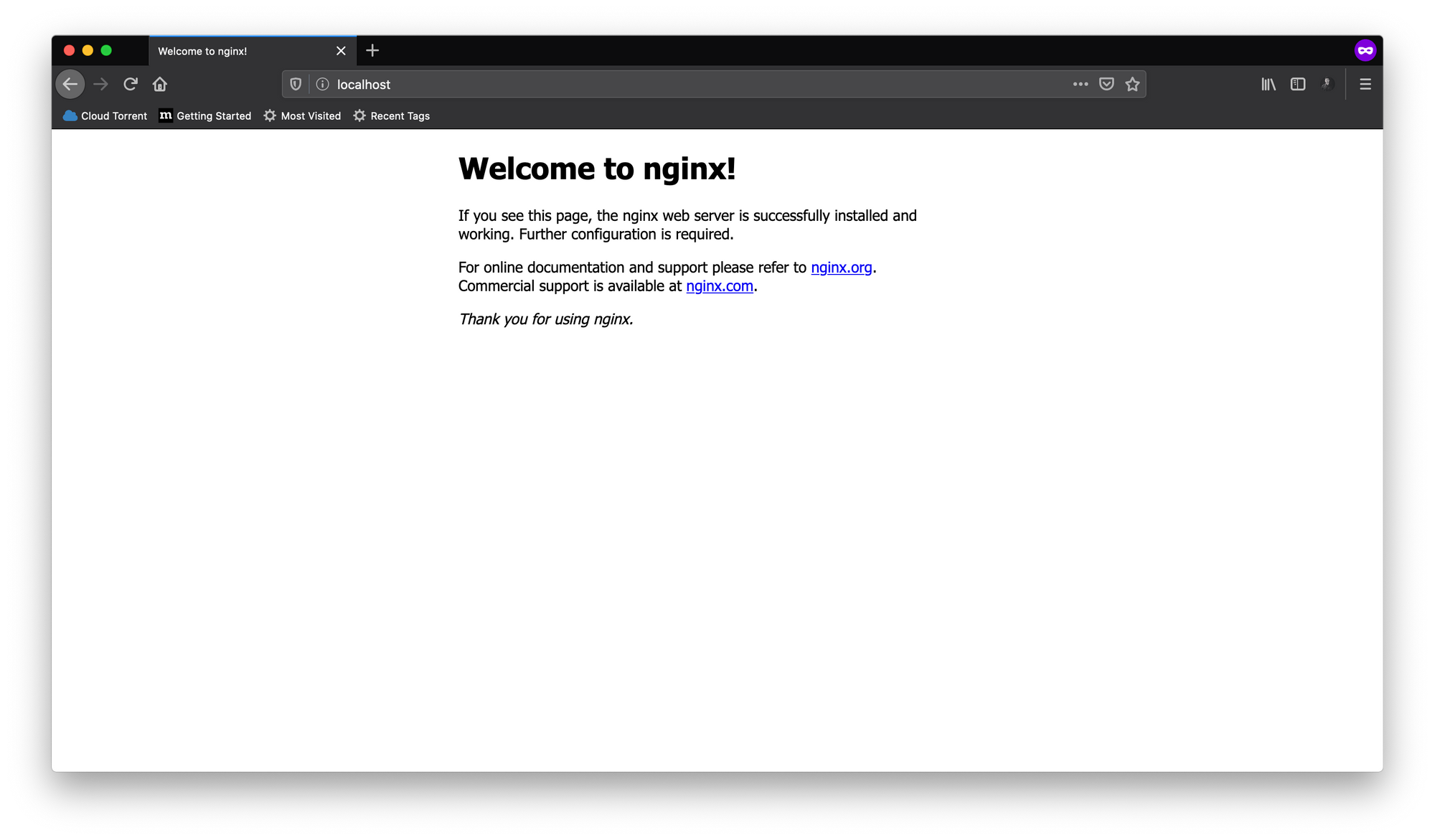
80:80の代わりにdocker run -p 8080:80 nginxを実行すると、ホストマシンのポート8080番でNginxサーバーが利用可能になります。しばらくしてポート番号を忘れた場合は、ダッシュボードを使用して確認できます。
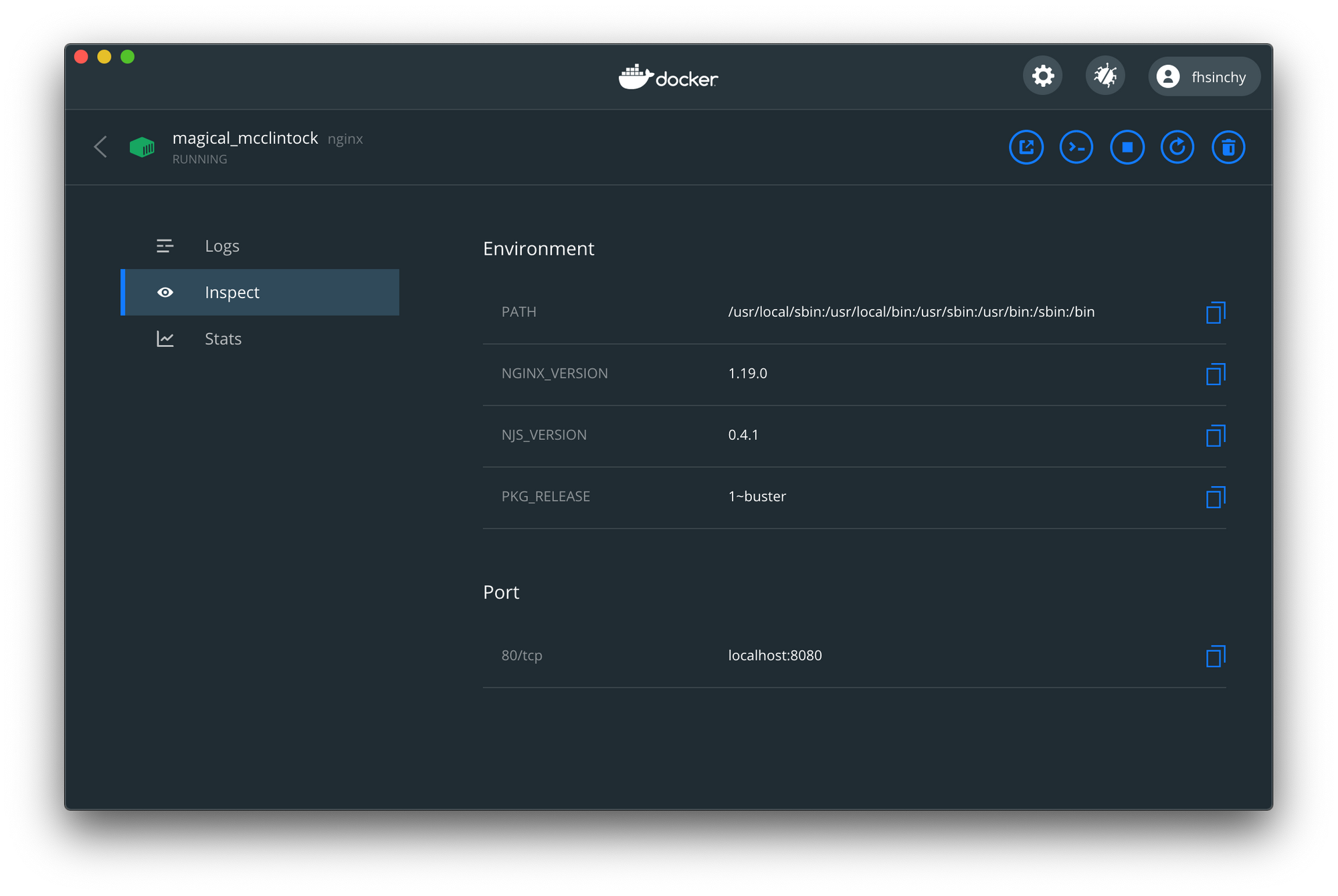
Inspectタブには、ポートマッピングに関する情報が含まれています。ご覧のとおり、ポート80番をコンテナからホストシステムのポート8080番にマッピングしました。
コンテナ分離のデモ
コンテナの概念を紹介したときから、コンテナは分離された環境であると言ってきました。隔離されているとは、ホストシステムだけでなく、他のコンテナからも意味します。
このセクションでは、この分離について理解するために少し実験を行います。2つのターミナルウィンドウを開き、次のコマンドを使用して2つのUbuntuコンテナインスタンスを実行します。
docker run -it ubuntu
ダッシュボードを開くと、2つのUbuntuコンテナが実行されていることがわかります。
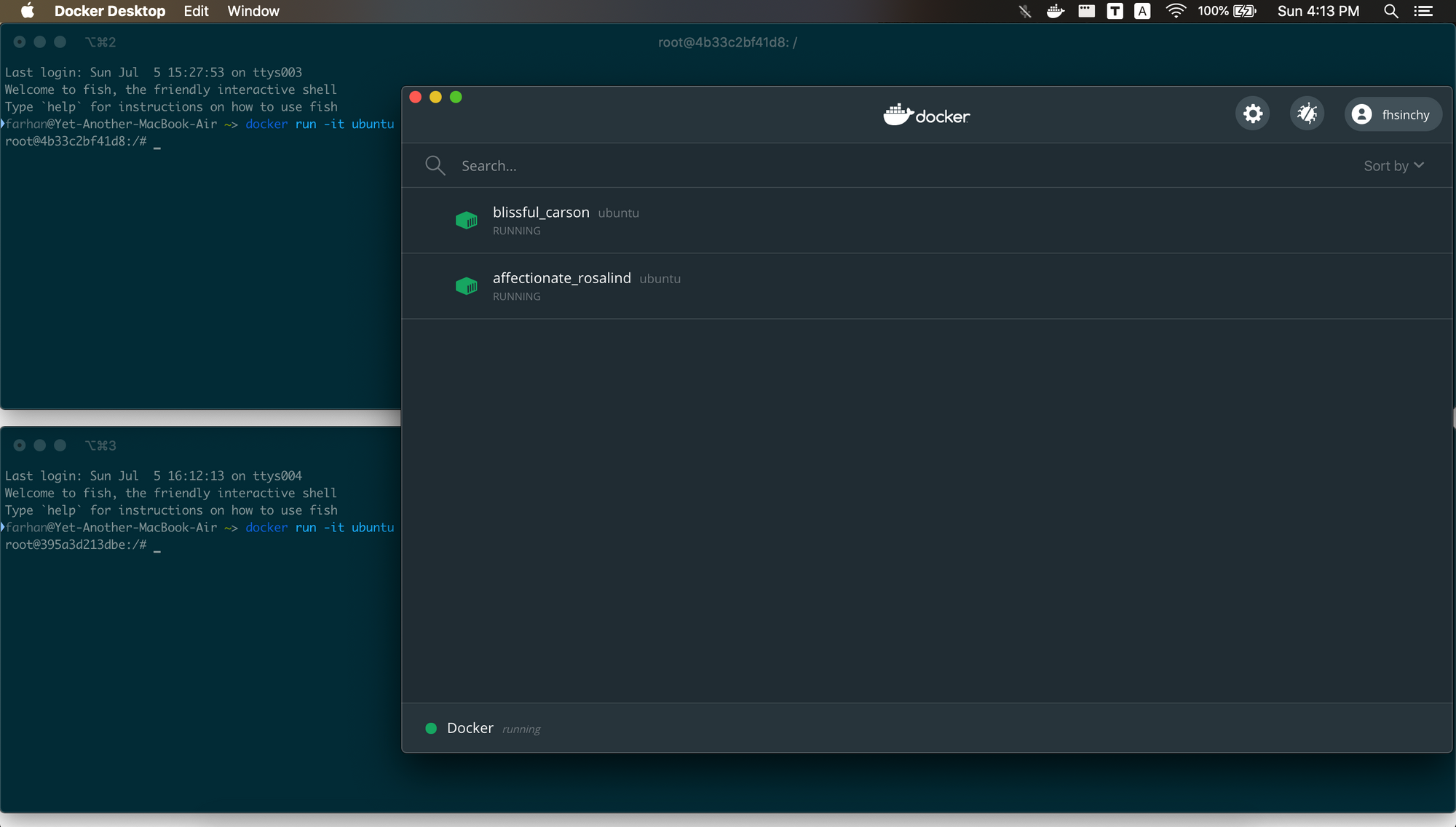
上のウィンドウで、次のコマンドを実行します。
mkdir hello-world
mkdirコマンドは新しいディレクトリを作成します。両方のコンテナのディレクトリのリストを表示するには、両方のコンテナ内でlsコマンドを実行します。
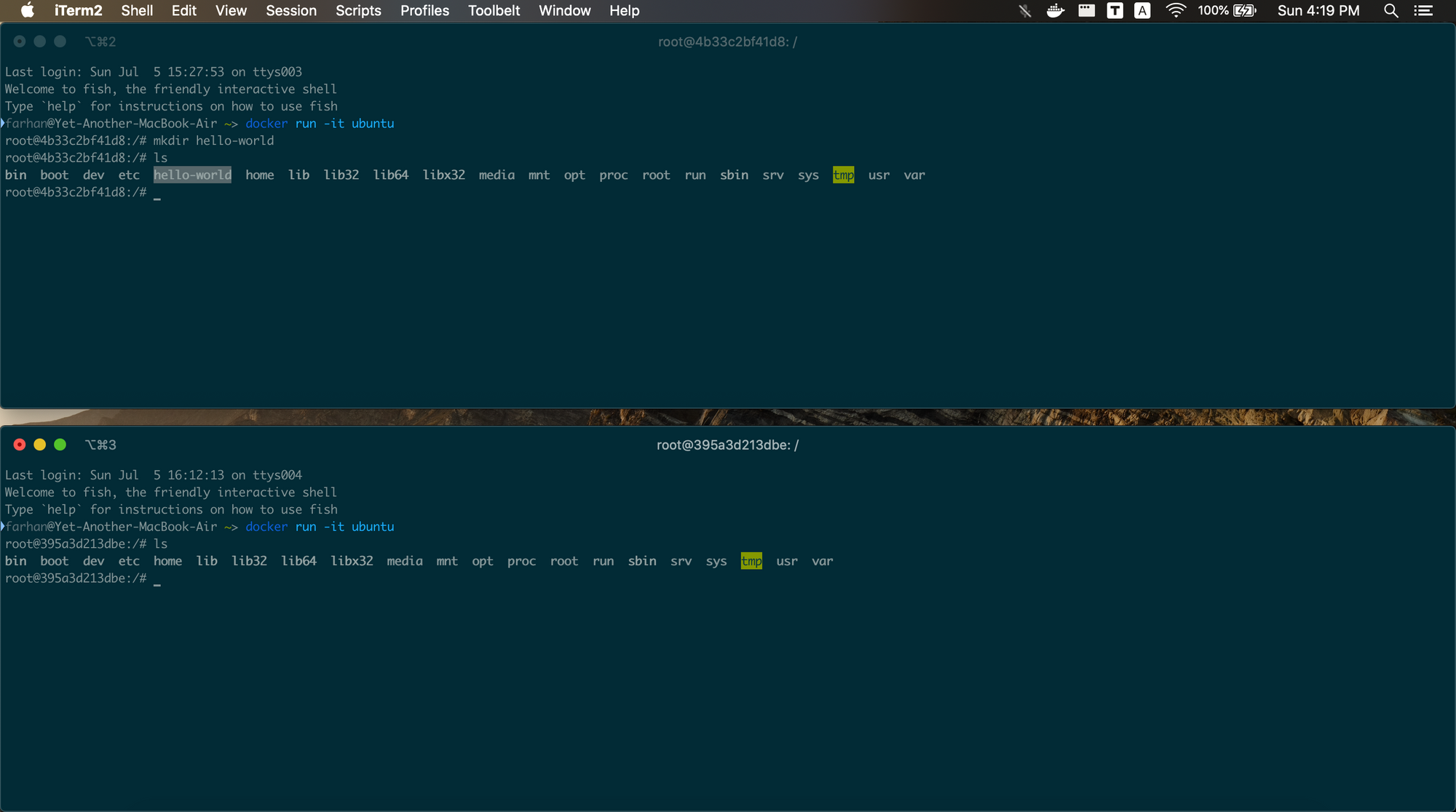
ご覧のように、hello-worldディレクトリは、下部のウィンドウではなく、上部のターミナルウィンドウで開いているコンテナ内に存在します。同じイメージから作成されたコンテナが互いに分離されていることを証明しています。
これは理解しておくべき重要なことです。しばらくコンテナ内で作業しているシナリオを想定します。次に、コンテナを「停止」し、翌日にもう一度docker run -it ubuntuを実行します。行った動作すべてが消失したことがわかります。
前のサブセクションから覚えていると思いますが、runコマンドは毎回新しいコンテナを作成して開始します。そのため、runコマンドではなく、startコマンドを使用して、以前に作成したコンテナを起動することを忘れないでください。
カスタムイメージの作成
Dockerクライアントを使用してコンテナを操作する多くの方法をしっかり理解したところで、今度はカスタムイメージの作成方法を学習します。
このセクションでは、イメージの構築、イメージからのコンテナの作成、および他のユーザーとの共有に関する多くの重要な概念を学びます。
以降のサブセクションに進む前にVisual Studio Codeと共に公式のDocker Extensionをインストールすることをお勧めします。
イメージ作成の基本
このサブセクションでは、Dockerfileの構造と一般的な手順に焦点を当てます。Dockerfileはテキストドキュメントであり、Dockerデーモンがイメージを作成してビルドするための一連の指示が含まれています。
イメージ作成の基本を理解するために、非常にシンプルなカスタムNodeイメージを作成します。始める前に、公式のnodeイメージがどのように機能するかを紹介します。次のコマンドを実行してコンテナを実行します。
docker run -it node
Nodeイメージは、起動時にNode REPLを開始するように構成されています。REPLはインタラクティブプログラムなので、-itフラグを使用します。
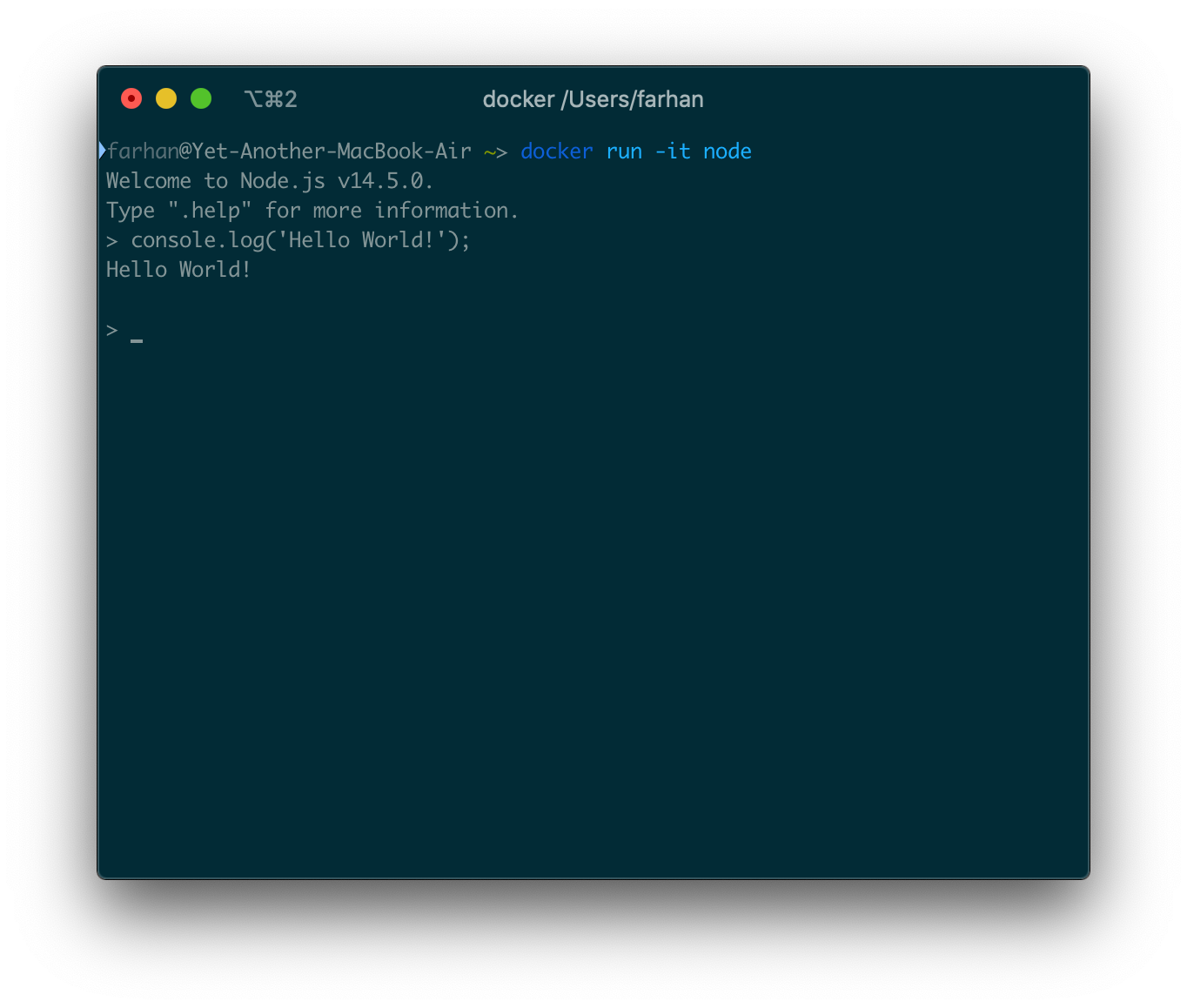
ここで有効なJavaScriptコードを実行できます。そのように機能するカスタムNodeイメージを作成します。
まず、コンピュータの任意の場所に新しいディレクトリを作成し、その中にDockerfileという名前の新しいファイルを作成します。コードエディター内でプロジェクトフォルダを開き、次のコードをDockerfileに配置します。
FROM ubuntu RUN apt-get update RUN apt-get install nodejs -y CMD [ "node" ]
前のサブセクションから、イメージに複数のレイヤーがあることを思い出してください。Dockerfileの各行は命令であり、各命令は新しいレイヤーを作成します。
Dockerfileを1行ずつ詳しく説明します。
FROM ubuntu
すべての有効なDockerfileは、FROM命令で始まる必要があります。この命令は、新しいビルドステージを開始し、ベースイメージを設定します。ubuntuをベースイメージとして設定することにより、Ubuntuイメージのすべての機能をイメージ内で使用できるようにする必要があります。
イメージでUbuntu機能を使用できるようになったので、Ubuntuパッケージマネージャー(apt-get)を使用してNodeをインストールできます。
RUN apt-get update RUN apt-get install nodejs -y
RUN命令は、現在のイメージ上の新しいレイヤーでコマンドを実行し、結果を保持します。したがって、次の手順では、Nodeを参照できます。これはこの手順でNodeをインストールしたためです。
CMD [ "node" ]
CMD命令の目的は、実行中のコンテナにデフォルトを提供することです。これらのデフォルトには実行可能ファイルを含めることも、実行可能ファイルを省略することもできます。その場合は、ENTRYPOINT命令を指定する必要があります。Dockerfileに含めることができるCMD命令は1つだけです。また、シングルクォーテーションは無効です。
このDockerfileからイメージをビルドするために、buildコマンドを使用します。コマンドの一般的な構文は次のとおりです。
docker build <ビルドコンテキスト>
buildコマンドにはDockerfileとビルドコンテキストが必要です。コンテキストは、指定された場所にあるファイルとディレクトリのセットです。Dockerはコンテキスト内でDockerfileを探し、それを使用してイメージを構築します。
そのディレクトリ内のターミナルウィンドウを開き、次のコマンドを実行します。
docker build .
現在のディレクトリを意味するビルドコンテキストとして.を渡しています。/src/Dockerfileのような別のディレクトリ内にDockerfileを置くと、コンテキストは./srcになります。
ビルドプロセスが完了するまでに時間がかかる場合があります。完了すると、ターミナルにテキストの壁が表示されます。
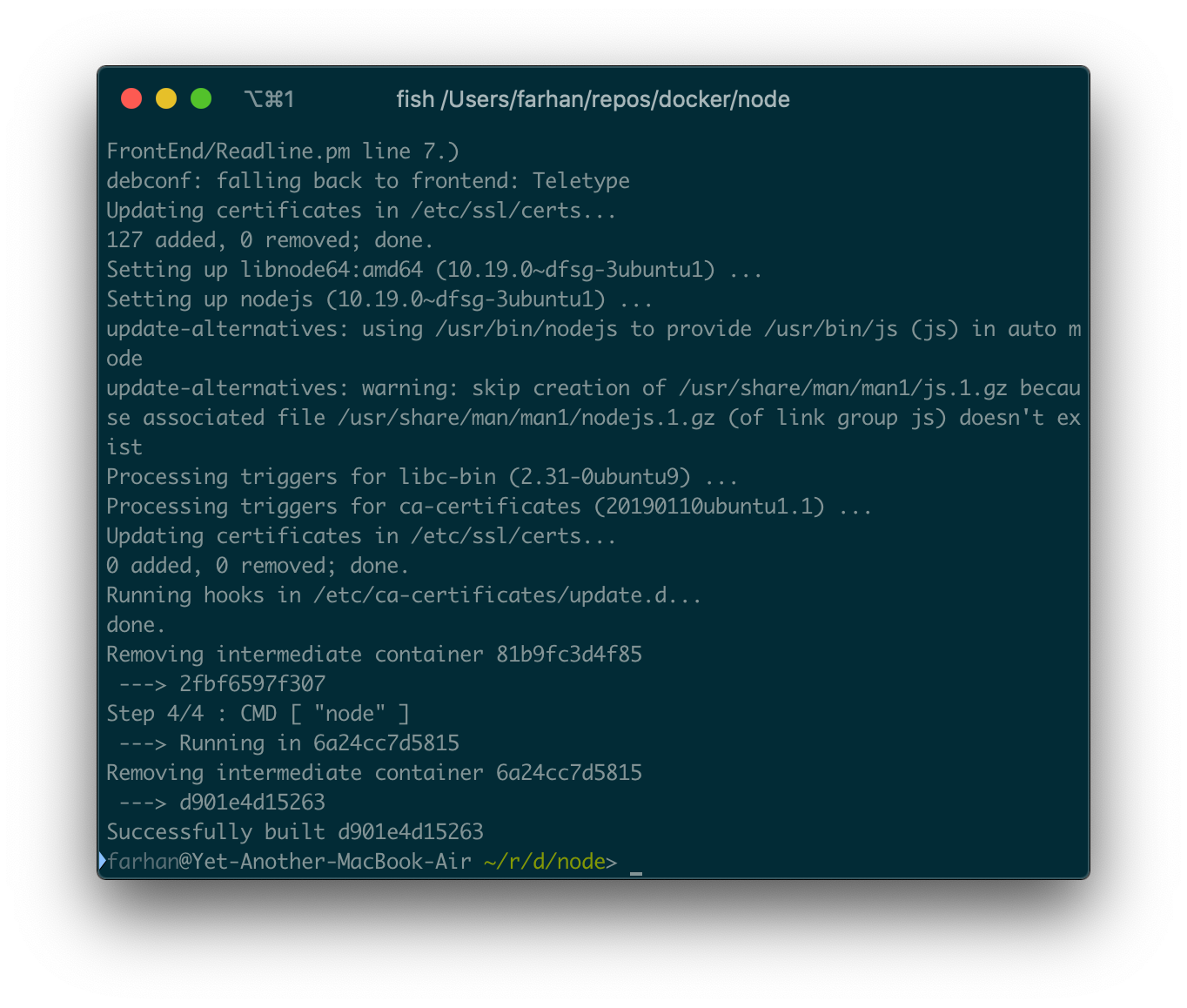
すべてがうまくいくと、最後にSuccessfully built d901e4d15263のようなものが表示されます。このランダムな文字列はイメージIDであり、コンテナIDではありません。このイメージIDでrunコマンドを実行して、新しいコンテナを作成して立ち上げることができます。
docker run -it d901e4d15263
Node REPLはインタラクティブプログラムであるため、-itオプションが必要であることを忘れないでください。コマンドを実行したらNode REPLにアクセスする必要があります。
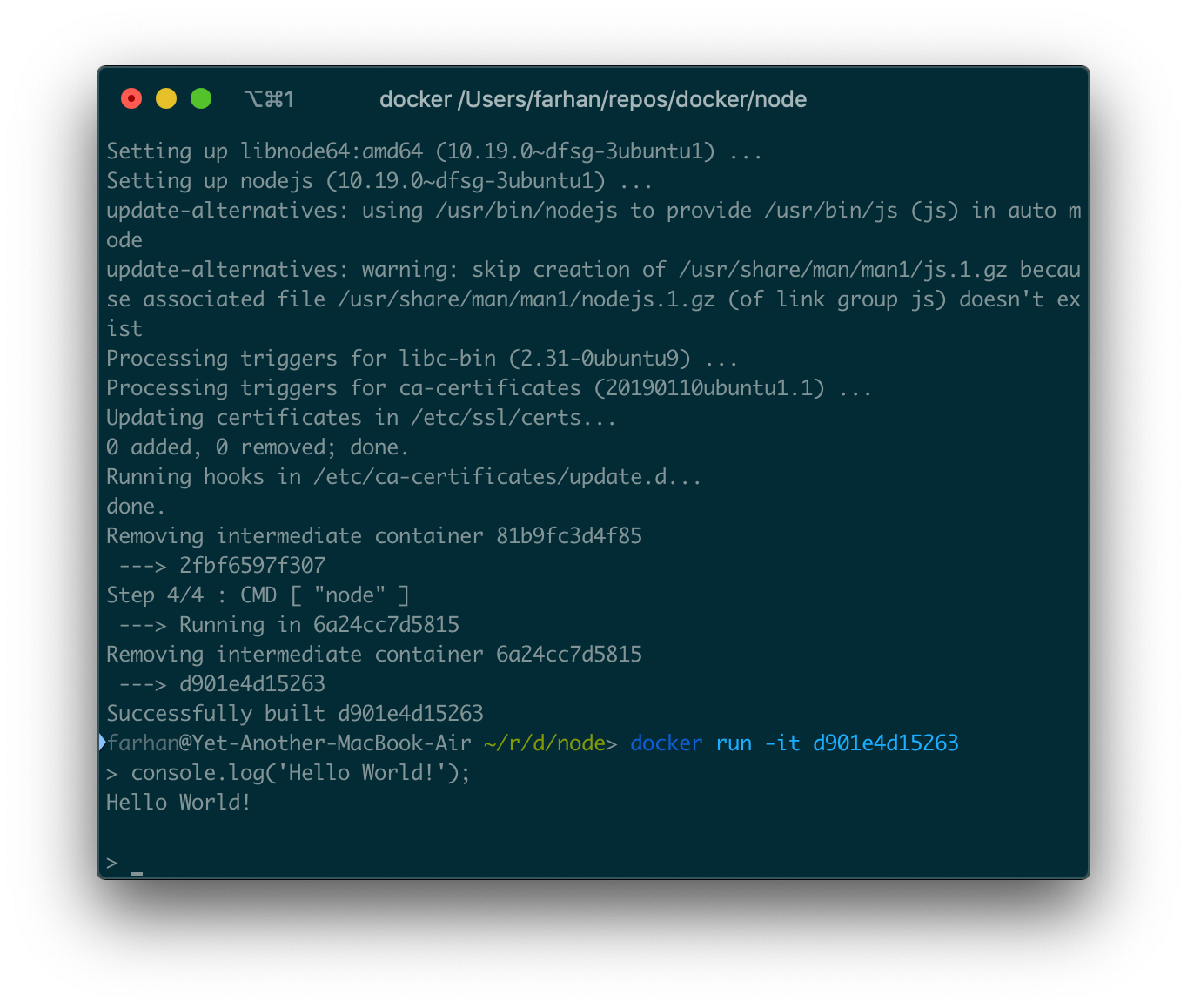
ここでは、公式のNodeイメージと同じように、任意の有効なJavaScriptコードを実行できます。
実行可能イメージを作成する
前のサブセクションの実行可能イメージの概念を思い出してください。イメージは通常の実行可能ファイルと同じように追加の引数を取ることができます。このサブセクションでは、作成方法を学習します。
カスタムbashイメージを作成し、前のサブセクションでUbuntuイメージで行ったように引数を渡します。空のディレクトリ内にDockerfileを作成することから始め、次のコードをその中に配置します。
FROM alpine RUN apk add --update bash ENTRYPOINT [ "bash" ]
alpineイメージをベースとして使用しています。Alpine Linuxは、セキュリティ指向で軽量なLinuxディストリビューションです。
Alpineにはデフォルトでbashが付属していません。したがって、2行目では、Alpineパッケージマネージャーであるapkを使用してbashをインストールします。AlpineのapkはUbuntuでいうapt-getです。最後の命令は、このイメージのエントリポイントとしてbashを設定します。ご覧のとおり、ENTRYPOINT命令はCMD命令と同じです。
イメージをビルドするには、次のコマンドを実行します。
docker build .
ビルドプロセスには時間がかかる場合があります。完了したら、新しく作成されたイメージIDを取得する必要があります。
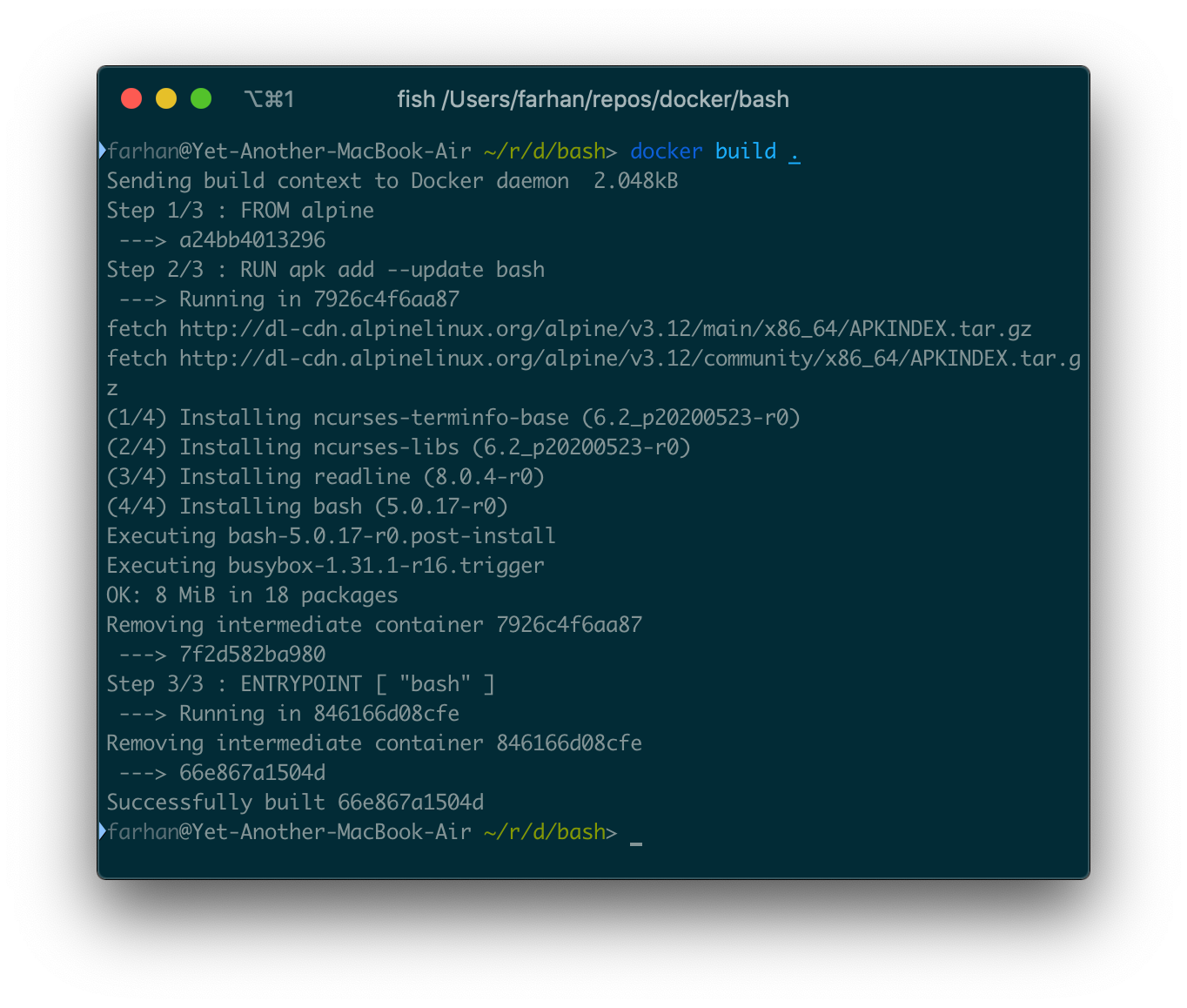
作成されたイメージからコンテナを実行するには、runコマンドを使用します。このイメージにはインタラクティブなエントリポイントがあるため、必ず-itオプションを使用してください。
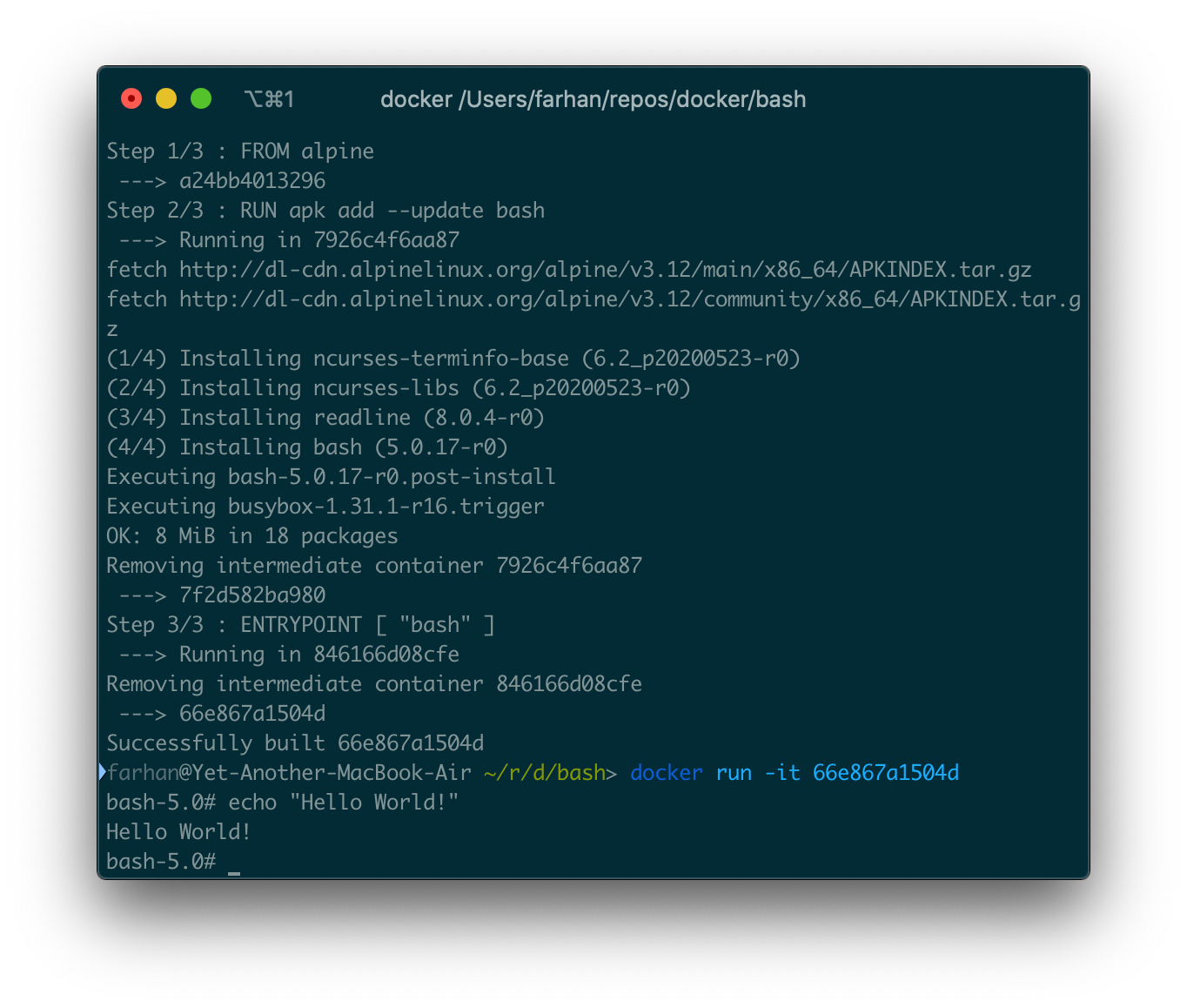
これで、Ubuntuコンテナで行ったように、このコンテナに任意の引数を渡すことができます。すべてのファイルとディレクトリのリストを表示するには、次のコマンドを実行できます。
docker run 66e867a1504d -c ls
-c lsオプションはbashに直接渡され、コンテナ内のディレクトリのリストを返す必要があります。
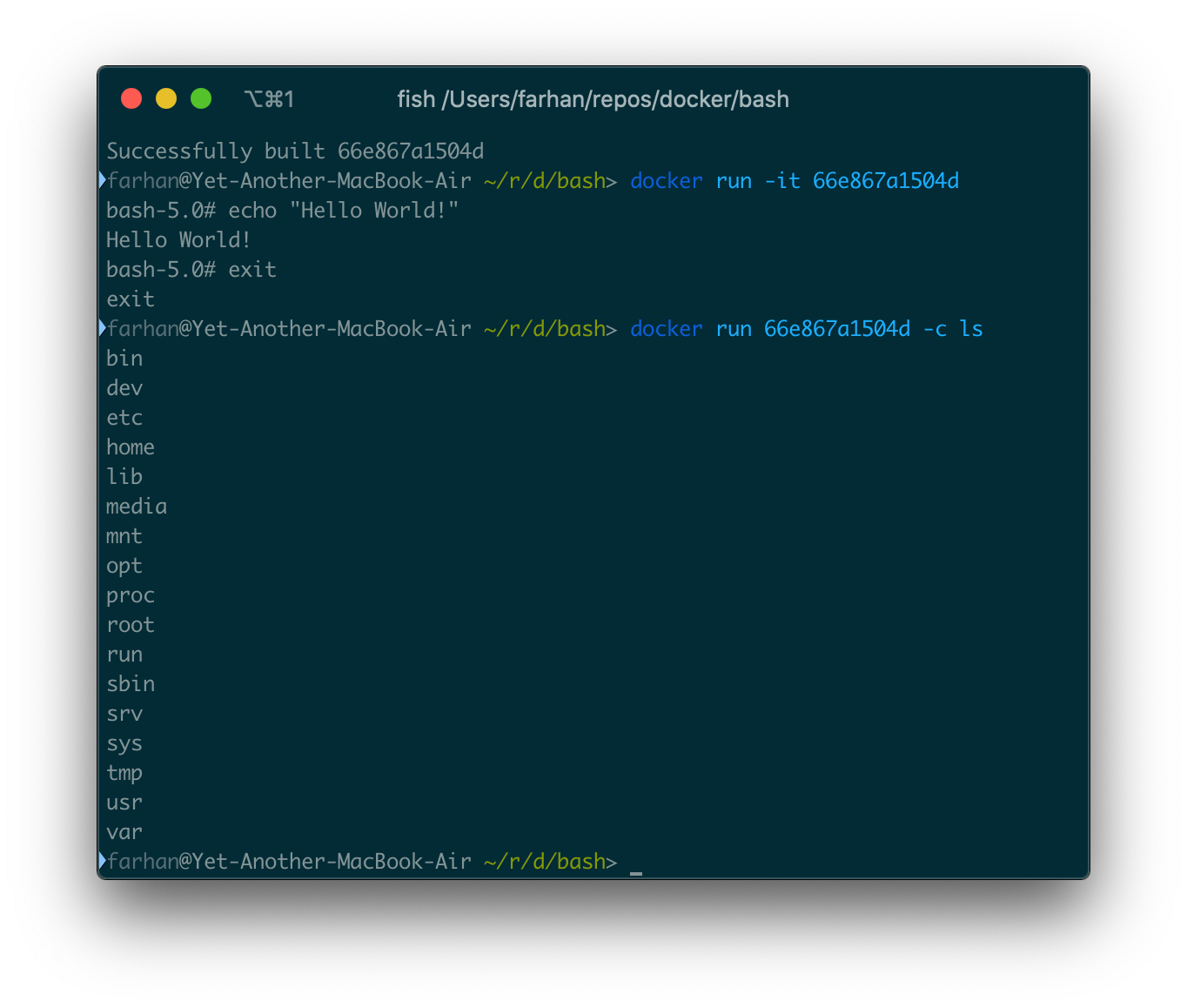
-cオプションはDockerクライアントとは何の関係もありません。これはbashコマンドラインオプションです。後続の文字列からコマンドを読み取ります。
Expressアプリケーションのコンテナ化
これまでは追加のファイルを含まないイメージのみを作成しました。このサブセクションでは、ソースファイルを含むプロジェクトをコンテナ化する方法を学習します。
プロジェクトコードリポジトリのクローンを作成した場合は、express-apiディレクトリ内に移動します。これは、ポート3000番で実行され、ヒットすると単純なJSONペイロードを返すREST APIです。
このアプリケーションを実行するには、次の手順を実行する必要があります。
npm installを実行して、必要な依存関係をインストールします。npm run startを実行してアプリケーションを起動します。
Dockerfileの手順を使用して上記のプロセスを複製するには、次の手順を実行する必要があります。
- Nodeアプリケーションを実行できるベースイメージを使用します。
package.jsonファイルをコピーし、npm run installを実行して依存関係をインストールします。- 必要なプロジェクトファイルをすべてコピーします。
npm run startを実行してアプリケーションを起動します。
次に、プロジェクトディレクトリ内に新しいDockerfileを作成し、次の内容をファイル中に配置します。
FROM node WORKDIR /usr/app COPY ./package.json ./ RUN npm install COPY . . CMD [ "npm", "run", "start" ]
ベースイメージとしてNodeを使用しています。WORKDIRは、WORKDIRのあとのRUN、CMD、ENTRYPOINT、COPY、およびADDのすべての命令の作業ディレクトリを設定します。これは、ディレクトリにcdするようなものです。
COPYは./package.jsonを作業ディレクトリにコピーします。前の行で作業ディレクトリを設定したので、.はコンテナ内の/usr/appを参照します。package.jsonがコピーされたら、RUNを使用して必要な依存関係をすべてインストールします。
CMDでは、npmを実行可能ファイルとして設定し、runとstartを引数として渡します。命令はコンテナ内でnpm run startとして解釈されます。
ここで、docker build .を使用してイメージをビルドし、結果としてのイメージIDを使用して新しいコンテナを実行します。アプリケーションはコンテナ内のポート3000番で実行されるため、マッピングすることを忘れないでください。
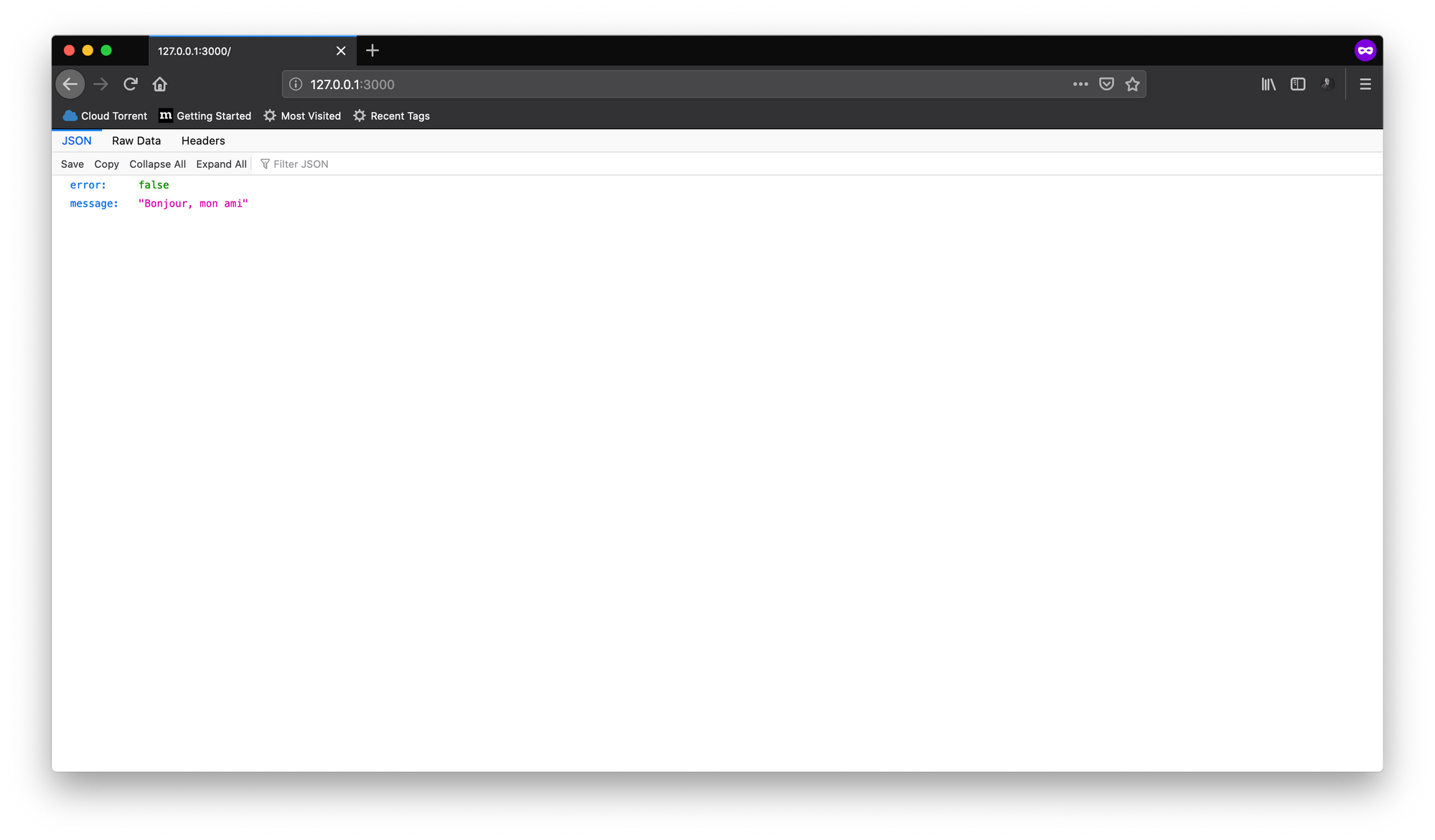
コンテナが正常に実行されたら、http://127.0.0.1:3000にアクセスすると、シンプルなJSONがレスポンスとして表示されます。ホストシステムから他のポートを使用した場合は、3000を書き換えてください。
ボリュームの操作
このサブセクションでは、非常に一般的なシナリオを紹介します。ReactまたはVueを使用して、モダンなフロントエンドアプリケーションで作業していると想定します。プロジェクトコードリポジトリをクローンしたら、vite-counterディレクトリ内に移動します。これは、npm init vite-appコマンドで初期化されたシンプルなVueアプリケーションです。
このアプリケーションを開発モードで実行するには、次の手順を実行する必要があります。
npm installを実行して、必要な依存関係をインストールします。npm run devを実行して、アプリケーションを開発モードで起動します。
Dockerfileの手順を使用して上記のプロセスを複製するには、次の手順を実行する必要があります。
- Nodeアプリケーションを実行できるベースイメージを使用します。
package.jsonファイルをコピーし、npm run installを実行して依存関係をインストールします。- 必要なプロジェクトファイルをすべてコピーします。
npm run devを実行して、アプリケーションを開発モードで起動します。
そこに新しくDockerfile.devを作成し、以下の内容を記述します。
FROM node WORKDIR /usr/app COPY ./package.json ./ RUN npm install COPY . . CMD [ "npm", "run", "dev" ]
空想ではなく、実際にpackage.jsonファイルをコピーし、依存関係をインストールして、プロジェクトファイルをコピーし、npm run devを実行して開発サーバーを起動しました。
次のコマンドを実行してイメージをビルドします。
docker build -f Dockerfile.dev .
Dockerは、ビルドのコンテキスト内でDockerfileを探すようにプログラムされています。しかし、ファイルにDockerfile.devという名前を付けたので、-fまたは--fileオプションを使用して、Dockerにファイル名を知らせる必要があります。最後の.は、以前と同様にコンテキストを示します。
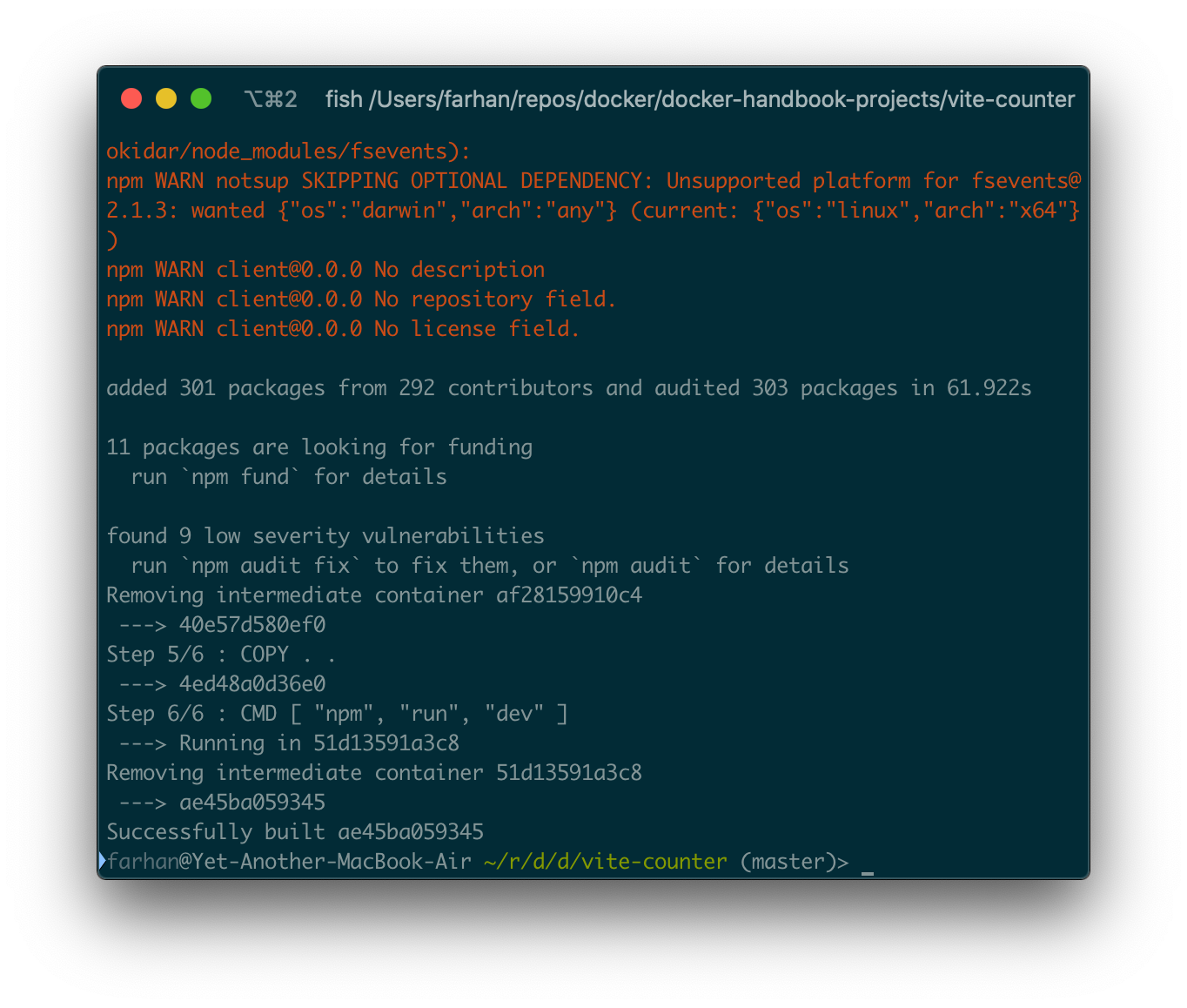
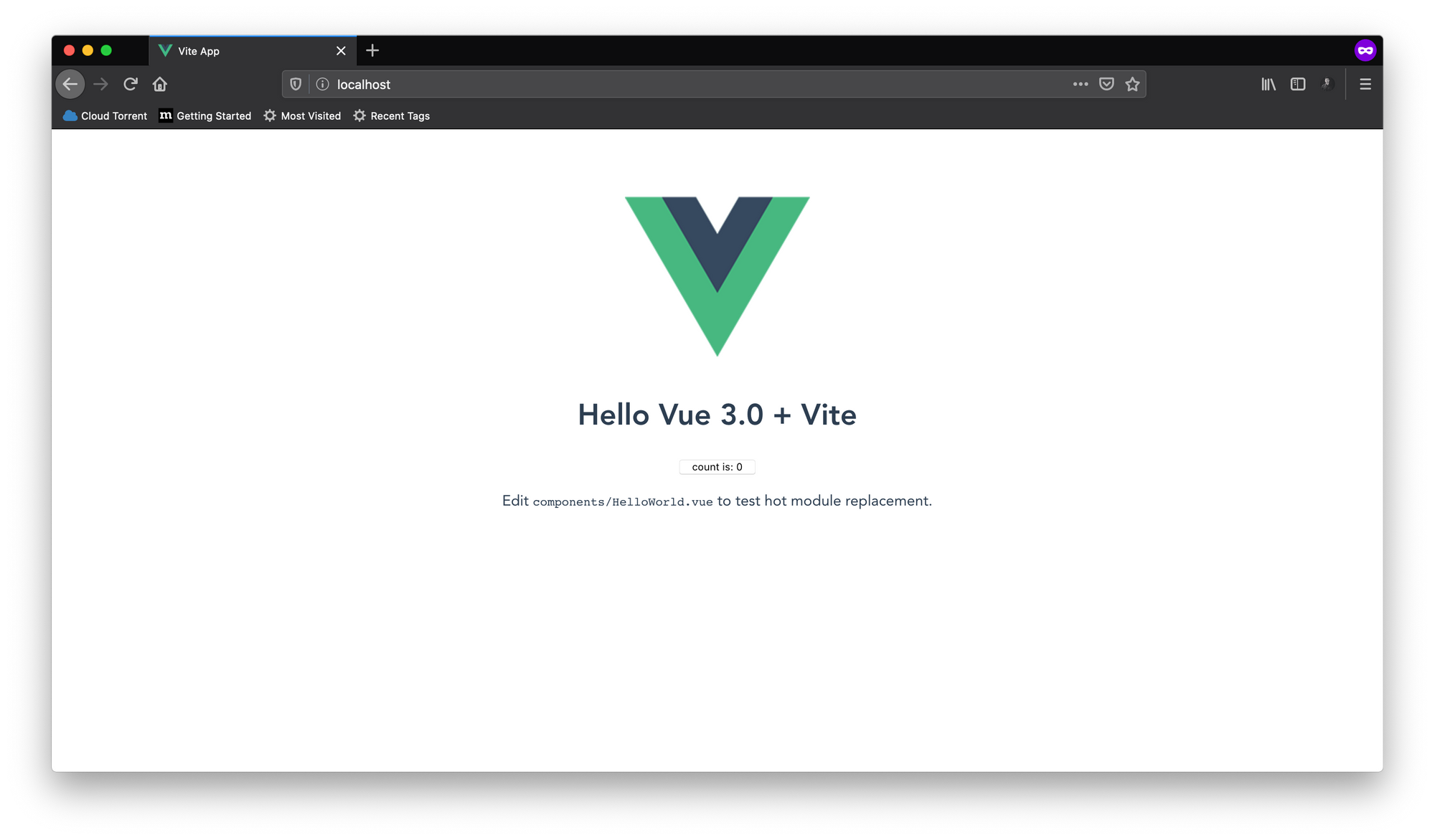
開発サーバーはコンテナ内のポート3000番で実行されるため、コンテナを作成して起動するときにポートをマップするようにしてください。私の方ではhttp://127.0.0.1:3000にアクセスして、アプリケーションにアクセスできます。
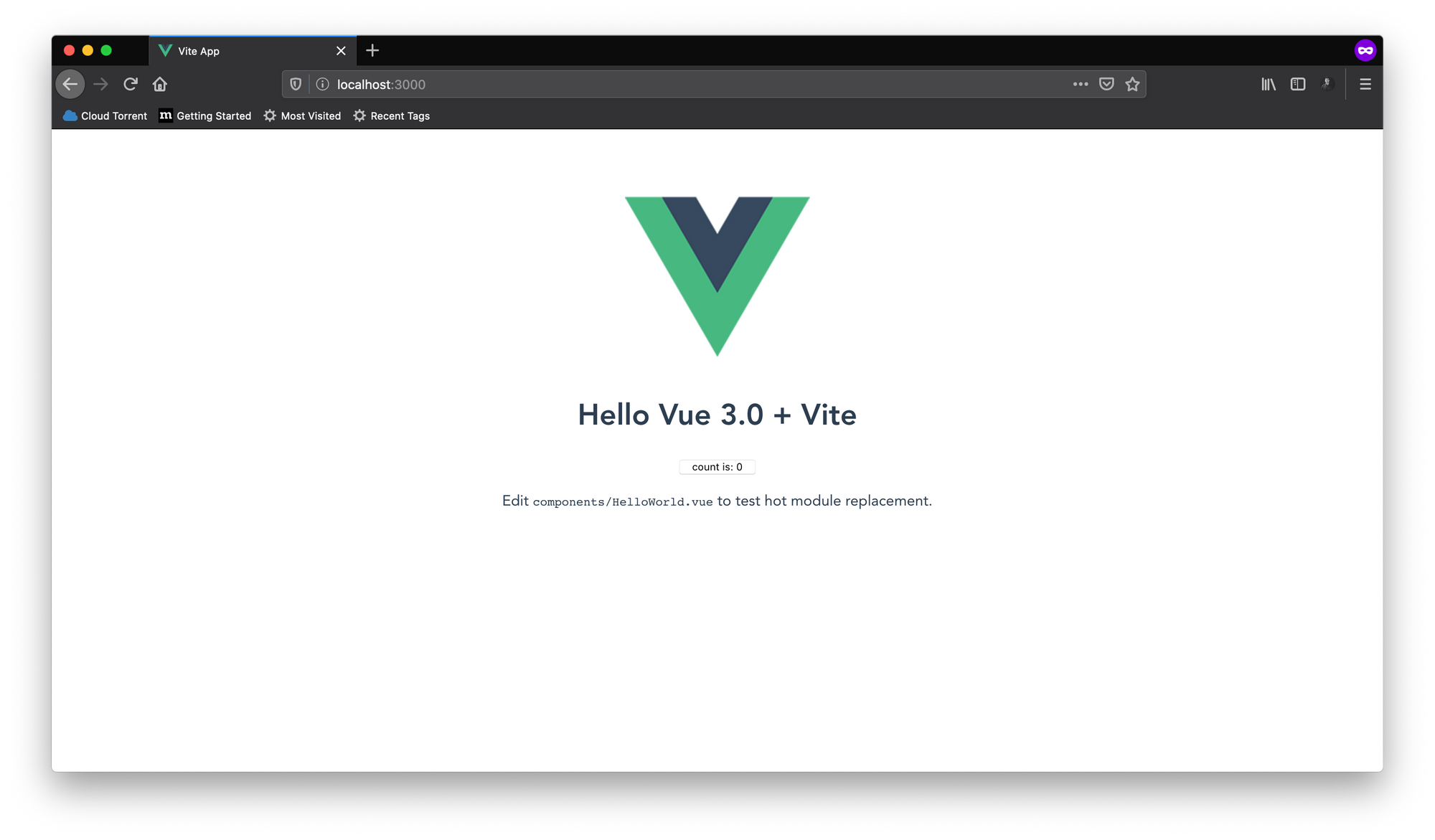
これは、新しいViteアプリケーションに付属するデフォルトのコンポーネントです。ボタンを押してカウントを増やすことができます。
すべての主要なフロントエンドフレームワークには、ホットリロード機能が付属しています。開発サーバーで実行中にコードに変更を加えた場合、変更はブラウザにすぐに反映されますが、一足先にこのプロジェクトのコードに変更を加えようとしても、ブラウザには何の変更も表示されません。
まあ、その理由はかなり簡単です。コードを変更する場合は、コンテナ内のコピーではなく、ホストシステムのコードを変更します。
この問題の解決策があります。コンテナ内にソースコードのコピーを作成する代わりに、コンテナにホストから直接ファイルにアクセスさせることができます。
そうするために、Dockerには、runコマンド用の-vまたは--volumeというオプションがあります。volumeオプションの一般的な構文は次のとおりです。
docker run -v <ホストディレクトリへの絶対パス>:<コンテナの作業ディレクトリへの絶対パス> <イメージID>
pwdシェルコマンドを使用して、現在のディレクトリの絶対パスを取得できます。私のホストディレクトリパスは/Users/farhan/repos/docker/docker-handbook-projects/vite-counter、コンテナアプリケーションの作業ディレクトリパスは/usr/app、イメージIDは8b632faffb17です。だから私のコマンドは次のようになります。
docker run -p 3000:3000 -v /Users/farhan/repos/docker/docker-handbook-projects/vite-counter:/usr/app 8b632faffb17
上記のコマンドを実行すると、sh: 1: vite: not foundというエラーが表示され、依存関係がコンテナ内に存在しないことを意味します。
このようなエラーが発生しないようにするには、ホストシステムに依存関係がインストールされている必要があります。ローカルシステムのnode_modulesフォルダを削除して、再試行してください。
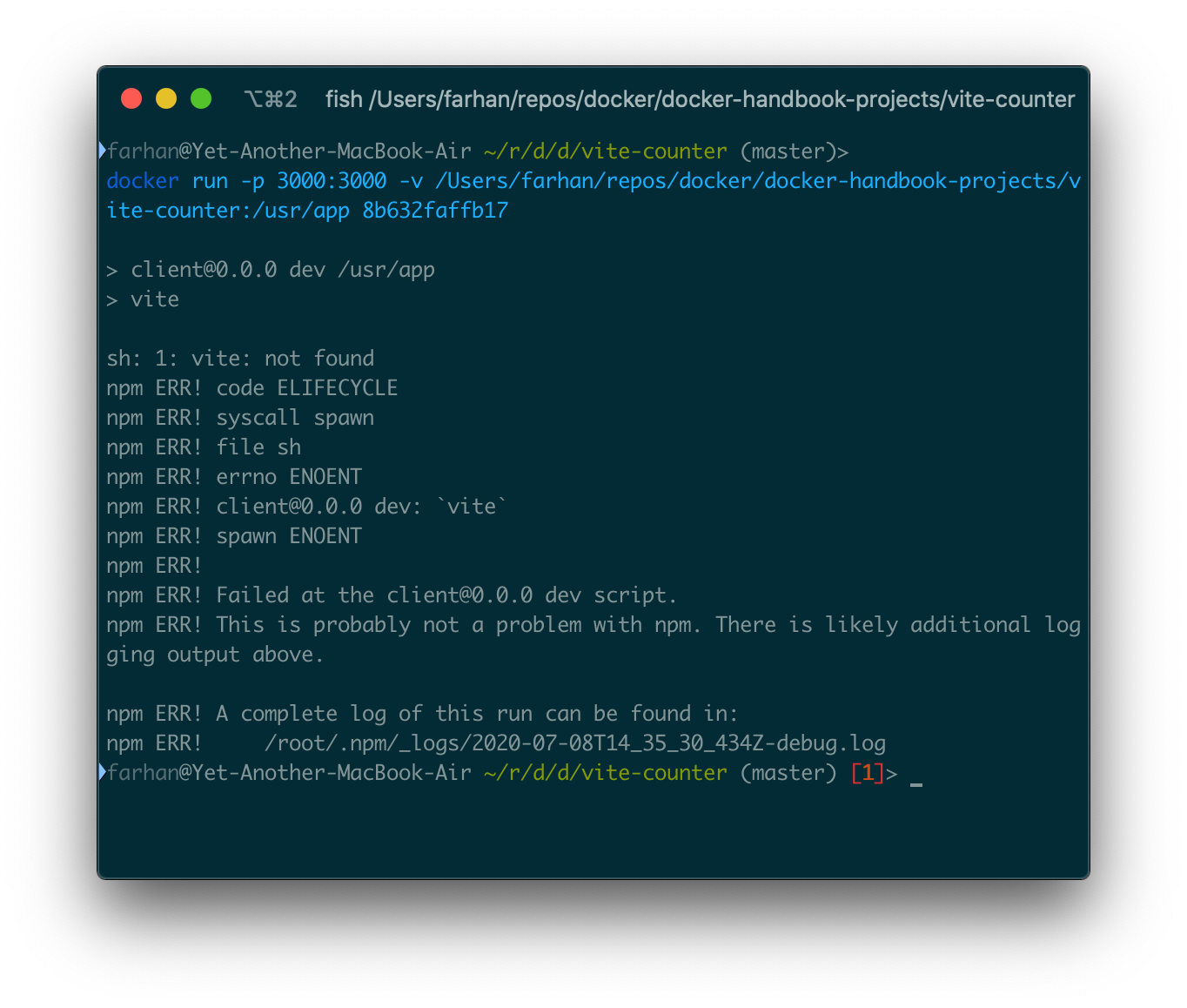
しかし、Dockerfile.devの4行目を見ると、RUN npm installが明確に記述されています。
これがなぜ起こっているのかを説明しましょう。ボリュームを使用する場合、コンテナはホストシステムから直接ソースコードにアクセスします。ご存じのとおり、ホストシステムには依存関係をインストールしていません。
依存関係をインストールすると問題を解決できますが、まったく理想的ではありません。一部の依存関係は、インストールするたびにソースからコンパイルされるためです。また、OSとしてWindowsまたはMacを使用している場合、OS用にビルドされたバイナリは、Linuxを実行しているコンテナ内では機能しません。
この問題を解決するには、Dockerが持っている2種類のボリュームについて知っておく必要があります。
- 名前付きボリューム:これらのボリュームには、コンテナ外部からの特定のソースがあります。たとえば、
-v ($PWD):/usr/appです。 - 匿名ボリューム:これらのボリュームには特定のソースがありません(例:
-v/usr/app/node_modules)。コンテナが削除されると、匿名ボリュームは手動でクリーンアップするまで残ります。
node_modulesディレクトリが上書きされないようにするには、匿名ボリューム内に配置する必要があります。これを行うには、前のコマンドを次のように変更します。
docker run -p 3000:3000 -v /usr/app/node_modules -v /Users/farhan/repos/docker/docker-handbook-projects/vite-counter:/usr/app 8b632faffb17
ここでは、新しい匿名ボリュームの追加のみを変更しました。ここでコマンドを実行すると、アプリケーションが実行されていることがわかります。何か変更したら、ブラウザですぐに変更を確認できます。デフォルトのヘッダーを少し変更しました。
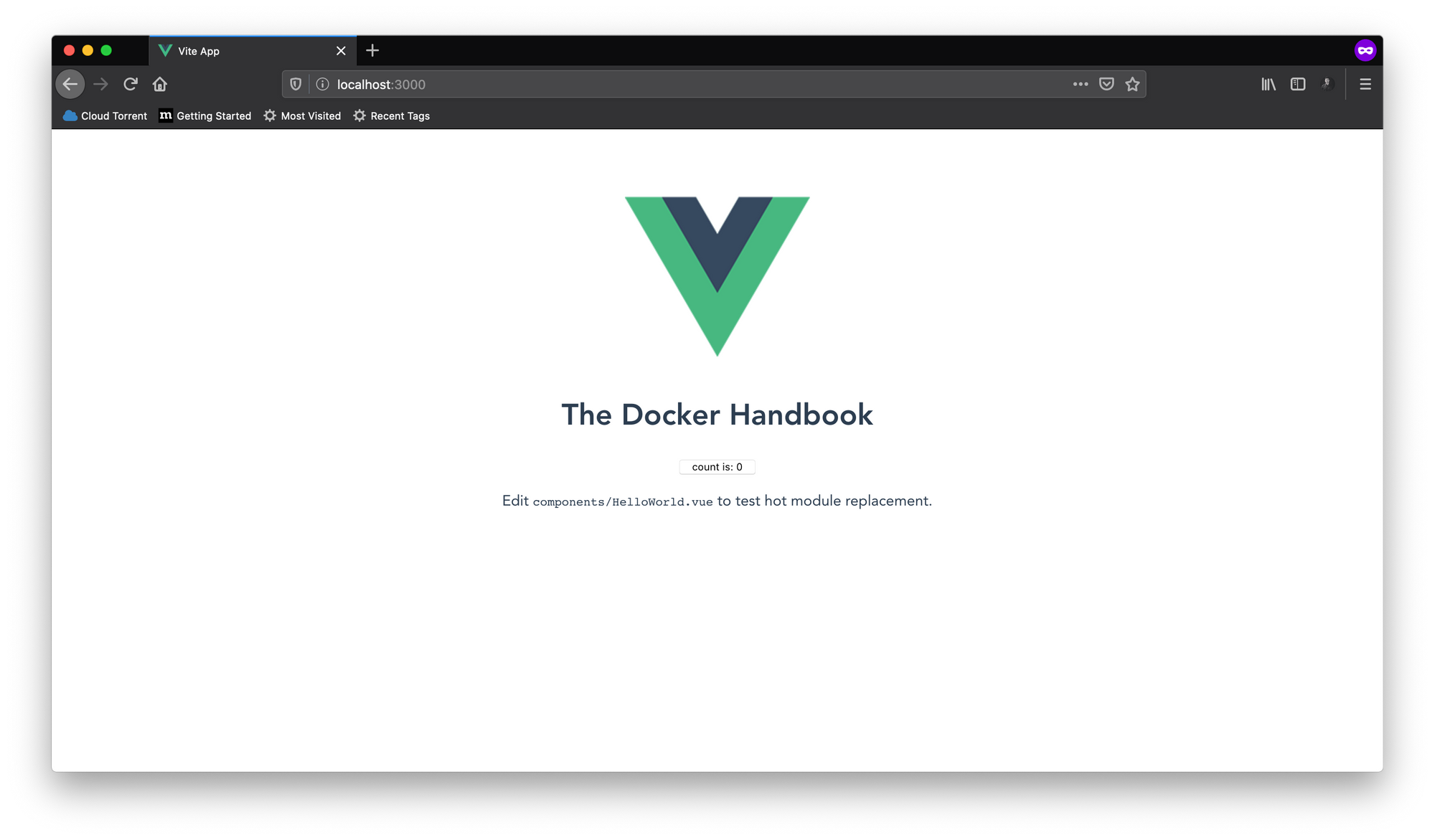
このコマンドは、繰り返し実行するには少し長すぎます。長いソースディレクトリの絶対パスの代わりにシェルコマンドで代用できます。
docker run -p 3000:3000 -v /usr/app/node_modules -v $(pwd):/usr/app 8b632faffb17
$(pwd)ビットは、現在のディレクトリへの絶対パスに置き換えられます。そのため、プロジェクトフォルダ内のターミナルウィンドウが開いていることを確認してください。
マルチステージビルド
Docker v17.05で導入されたマルチステージビルドは素晴らしい機能です。このサブセクションでは、vite-counterアプリケーションを再び使用します。
前のサブセクションでは、明確に開発サーバーを実行するためのDockerfile.devファイルを作成しました。VueまたはReactアプリケーションのプロダクションビルドを作成することは、多段階ビルドプロセスの完璧な例です。
最初に、次の図でプロダクションビルドがどのように機能するかを示します。

図からわかるように、ビルドプロセスには2つのステップまたはステージがあります。それらは次のとおりです。
npm run buildを実行すると、アプリケーションがひとくくりのJavaScript、CSS、およびindex.htmlファイルにコンパイルされます。プロダクションビルドは、プロジェクトルートの/distディレクトリ内で利用できます。ただし、開発バージョンとは異なり、プロダクションビルドには手の込んだサーバーが付属していません。- プロダクションファイルでサーバーを立ち上げるには、Nginxを使用する必要があります。ステージ1でビルドされたファイルをNginxのデフォルトのドキュメントルートにコピーし、利用可能にします。
前の2つのプロジェクトで行ったような手順を確認したい場合は、次のようになります。
- Nodeアプリケーションを実行できるベースイメージ(node)を使用します。
package.jsonファイルをコピーし、npm run installを実行して依存関係をインストールします。- 必要なプロジェクトファイルをすべてコピーします。
npm run buildを実行してプロダクションビルドを作成します。- 本番ファイルの実行を可能にする別のベースイメージ(nginx)を使用します。
- 本番ファイルを
/distディレクトリからデフォルトのドキュメントルート(/usr/share/nginx/html)にコピーします。
さあ、作業に取り掛かりましょう。vite-counterプロジェクトディレクトリ内に新しいDockerfileを作成します。Dockerfileの内容は次のとおりです。
FROM node as builder WORKDIR /usr/app COPY ./package.json ./ RUN npm install COPY . . RUN npm run build FROM nginx COPY --from=builder /usr/app/dist /usr/share/nginx/html
まず複数のFROMがあることに気づいたかもしれません。マルチステージビルドプロセスでは、複数のFROMを使用することができます。最初のFROMは、nodeをベースイメージとして設定し、依存関係をインストールし、すべてのプロジェクトファイルをコピーして、npm run buildを実行します。最初のステージをbuilderと命名します。
次に、第2段階では、ベースイメージとしてnginxを使用します。第1ステージで構築された/usr/app/distディレクトリから第2ステージのusr/share/nginx/htmlディレクトリにすべてのファイルをコピーします。COPYの--fromオプションを使用すると、ステージ間でファイルをコピーできます。
イメージをビルドするには、次のコマンドを実行します。
docker build .
今回はDockerfileという名前のファイルを使用しているため、ファイル名を明示的に宣言する必要はありません。ビルドプロセスが完了したら、イメージIDを使用して新しいコンテナを実行します。Nginxはデフォルトでポート80番で実行されるため、マッピングすることを忘れないでください。
コンテナを正常に起動したら、http://127.0.0.1:80にアクセスすると、カウンターアプリが実行されているのがわかります。ホストシステムから他のポートを使用した場合は、80を書き換えてください。
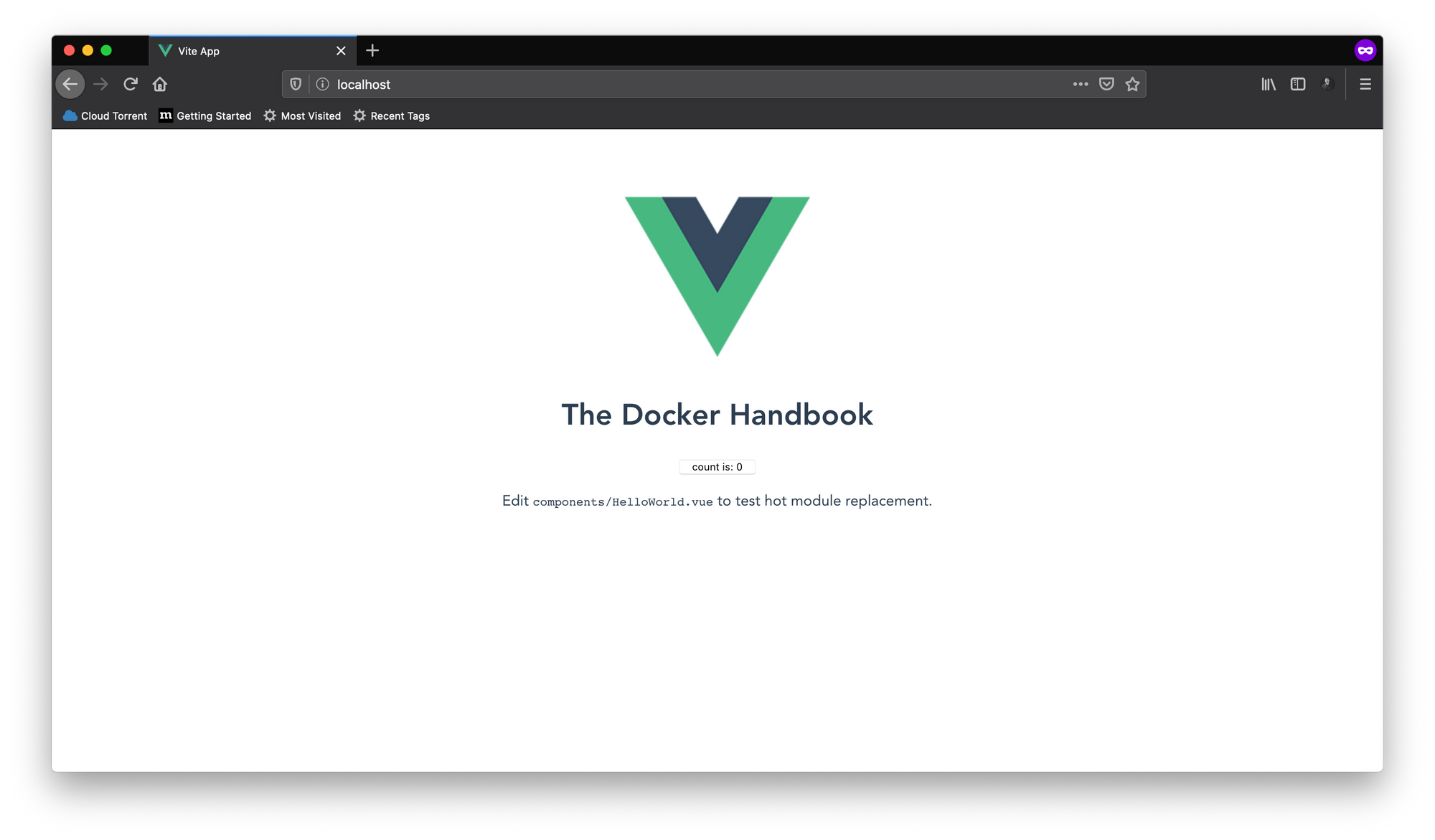
このマルチステージビルドプロセスからの出力イメージは、ビルドされたファイルのみを含み、追加のデータを含まないNginxベースのイメージです。その結果、サイズが最適化され、軽量になっています。
ビルドされたイメージをDocker Hubにアップロードする
あなたはすでにかなり多くの画像を構築しました。このサブセクションでは、画像のタグ付けとDocker Hubへのアップロードについて学びます。先に進んで、無料のアカウントDocker Hubにサインアップしてください。
アカウントを作成したら、Dockerメニューを使用してログインします。
または、ターミナルからコマンドを使用してログインできます。コマンドの一般的な構文は次のとおりです。
docker login -u <DockerのID> --password <Dockerのパスワード>
ログインが成功すると、ターミナルにLogin Succeededのようなものが表示されます。
これでイメージをアップロードする準備が整いました。イメージをアップロードするには、まずそれらにタグを付ける必要があります。プロジェクトコードリポジトリのクローンを作成した場合は、vite-counterプロジェクトフォルダー内のターミナルウィンドウを開きます。
buildコマンドで-tまたは--tagオプションを使用してイメージにタグを付けることができます。このオプションの一般的な構文は次のとおりです。
docker build -t <タグ> <ビルドのコンテキスト>
タグの一般的な規則は次のとおりです。
<DockerのID>/<イメージ名>:<イメージのバージョン>
私のDocker IDはfhsinchyなので、画像にvite-counterという名前を付けたい場合、コマンドは次のようになります。
docker build -t fhsinchy/vite-controller:1.0 .
コロンの後にバージョンを定義しない場合、latestが自動的に使用されます。すべてがうまくいけば、ターミナルにSuccessfully tagged fhsinchy/vite-controller:1.0のようなものが表示されるはずです。私の場合、バージョンを定義していません。
このイメージをHubにアップロードするには、pushコマンドを使用できます。コマンドの一般的な構文は次のとおりです。
docker push <DockerのID>/<イメージタグとバージョン>
fhsinchy/vite-counterイメージをアップロードするには、コマンドは次のようにする必要があります。
docker push fhsinchy/vite-counter
プッシュが完了すると、次のようなテキストが表示されます。
Hubのイメージは誰でも見ることができます。
このイメージからコンテナを実行するための一般的な構文は次のとおりです。
docker run <DockerのID>/<イメージタグとバージョン>
このアップロードされたイメージを使用してvite-counterアプリケーションを実行するには、次のコマンドを実行します。
docker run -p 80:80 fhsinchy/vite-counter
そして、あなたはvite-counterアプリケーションが以前と同じように実行されているのを見るはずです。
任意のアプリケーションをコンテナ化し、Docker Hubまたはその他のレジストリを介してそれらを配布して、実行またはデプロイをとても簡単にすることができます。
Docker Composeを使用したマルチコンテナアプリケーションの操作
これまでは、1つのコンテナのみで構成されるアプリケーションのみを扱ってきました。 次に、複数のコンテナを持つアプリケーションを想定します。おそらく、データベースサービスが適切に機能するために必要なAPI、またはバックエンドAPIとフロントエンドアプリケーションを一緒に使用する必要があるフルスタックアプリケーションなどがあります。
このセクションでは、Docker Composeというツールを使用して、このようなアプリケーションを操作する方法について学びます。
Dockerのドキュメントによると下記のように記述されています。
Composeは、マルチコンテナのDockerアプリケーションを定義して実行するためのツールです。Composeでは、YAMLファイルを使用してアプリケーションサービスを設定します。次に、1つのコマンドで、構成からすべてのサービスを作成して開始します。
Composeはすべての環境で機能しますが、開発とテストにより重点を置いています。本番環境でComposeを使用することはお勧めしません。
Docker Composeの基本
プロジェクトコードリポジトリのクローンを作成した場合は、notes-apiディレクトリ内に移動します。これは、ノートを作成、読み取り、更新、および削除できる単純なCRUD APIです。アプリケーションは、データベースシステムとしてPostgreSQLを使用します。
プロジェクトにはすでにDockerfile.devファイルがありました。ファイルの内容は次のとおりです。
FROM node:lts WORKDIR /usr/app COPY ./package.json . RUN npm install COPY . . CMD [ "npm", "run", "dev" ]
前のセクションで書いたものと同じです。package.jsonファイルをコピーし、依存関係をインストールして、プロジェクトファイルをコピーし、npm run devを実行して開発サーバーを起動します。
Composeの使用は、基本的に3つのステップのプロセスです。
Dockerfileを使用し、アプリを定義するので、どこでも再現できます。- アプリを構成するサービスを
docker-compose.ymlで定義して、隔離された環境で一緒に実行できるようにします。 docker-compose upを実行すると、Composeが起動し、アプリ全体が実行されます。
サービスは基本的に、いくつかの追加要素を持つコンテナです。最初のYMLファイルを一緒に書き始める前に、このアプリケーションの実行に必要なサービスをリストアップしましょう。2つしかありません。
api- プロジェクトルートのDockerfile.devファイルを使用して実行されるExpressアプリケーションコンテナ。db- 公式のpostgresイメージを使用して実行されるPostgreSQLインスタンス。
プロジェクトルートで新しいdocker-compose.ymlファイルを作成し、最初のサービスを一緒に定義しましょう。.ymlまたは.yaml拡張子を使用できます。どちらも問題なく動作します。最初にコードを記述してから、コードを1行ずつ詳しく説明します。dbサービスのコードは次のとおりです。
version: "3.8"
services:
db:
image: postgres:12
volumes:
- ./docker-entrypoint-initdb.d:/docker-entrypoint-initdb.d
environment:
POSTGRES_PASSWORD: 63eaQB9wtLqmNBpg
POSTGRES_DB: notesdb
すべての有効なdocker-compose.ymlファイルは、ファイルバージョンを定義することから始まります。執筆時点では、3.8が最新バージョンです。最新バージョンはこちらで調べることができます。
YMLファイル内のブロックは、インデントによって定義されます。私は各ブロックを通して、それらが何をするかを説明します。
servicesブロックは、アプリケーション内の各サービスまたはコンテナの定義を保持します。dbはservicesブロック内のサービスです。
dbブロックはアプリケーションの新しいサービスを定義し、コンテナを開始するために必要な情報を保持します。コンテナを実行するには、すべてのサービスに事前に構築されたイメージまたはDockerfileが必要です。dbサービスには、公式のPostgreSQLイメージを使用しています。
プロジェクトルートのdocker-entrypoint-initdb.dディレクトリには、データベースのテーブルをセットアップするためのSQLファイルが含まれています。このディレクトリは、初期化スクリプトを保持するためのものです。docker-compose.ymlファイル内のディレクトリをコピーする方法はないため、ボリュームを使用する必要があります。
environmentブロックは環境変数を保持します。有効な環境変数のリストは、Docker Hubのpostgres image pageにあります。POSTGRES_PASSWORD変数はサーバーのデフォルトのパスワードを設定し、POSTGRES_DBは指定された名前で新しいデータベースを作成します。
次に、apiサービスを追加します。次のコードをファイルに追加します。インデントとdbサービスを一致させるように注意してください。
##
## インデントを調整してください
##
api:
build:
context: .
dockerfile: Dockerfile.dev
volumes:
- /usr/app/node_modules
- ./:/usr/app
ports:
- 3000:3000
environment:
DB_CONNECTION: pg
DB_HOST: db ## データベースサービスと同じ名前を指定
DB_PORT: 5432
DB_USER: postgres
DB_DATABASE: notesdb
DB_PASSWORD: 63eaQB9wtLqmNBpg
apiサービス用のビルド済みイメージはありませんが、Dockerfile.devファイルがあります。buildブロックはビルドのcontextと使用するDockerfileのfilenameを定義します。ファイルの名前がDockerfileのみの場合、filenameは不要です。
ボリュームのマッピングは、前のセクションで見たものと同じです。node_modulesディレクトリ用の1つの匿名ボリュームとプロジェクトルート用の1つの名前付きボリュームです。
ポートマッピングも前のセクションと同じように機能します。構文は<ホストシステムポート>:<コンテナポート>です。コンテナのポート3000番をホストシステムのポート3000番にマッピングしています。
environmentブロックでは、データベース接続のセットアップに必要な情報を定義しています。アプリケーションはKnex.jsをORMとして使用して、データベースに接続するためにこれらの情報を必要とします。DB_PORT: 5432とDB_USER: postgresはすべてのPostgreSQLサーバーのデフォルトです。DB_DATABASE: notesdbおよびDB_PASSWORD: 63eaQB9wtLqmNBpgは、dbサービスの値と一致する必要があります。DB_CONNECTION: pgは、PostgreSQLを使用していることをORMに示します。
docker-compose.ymlファイルで定義されているすべてのサービスは、サービス名を使用してホストとして使用できます。そのため、apiサービスは、127.0.0.1のような値ではなくホストとして扱うことで、実際にdbサービスに接続できます。そのため、DB_HOSTの値をdbに設定しています。
docker-compose.ymlファイルが完成したので、アプリケーションを起動します。Composeアプリケーションは、dokcer-composeと呼ばれるCLIツールを使用してアクセスできます。Compose用のdocker-composeCLIは、DockerでいうdockerCLIです。サービスを開始するには、次のコマンドを実行します。
docker compose up
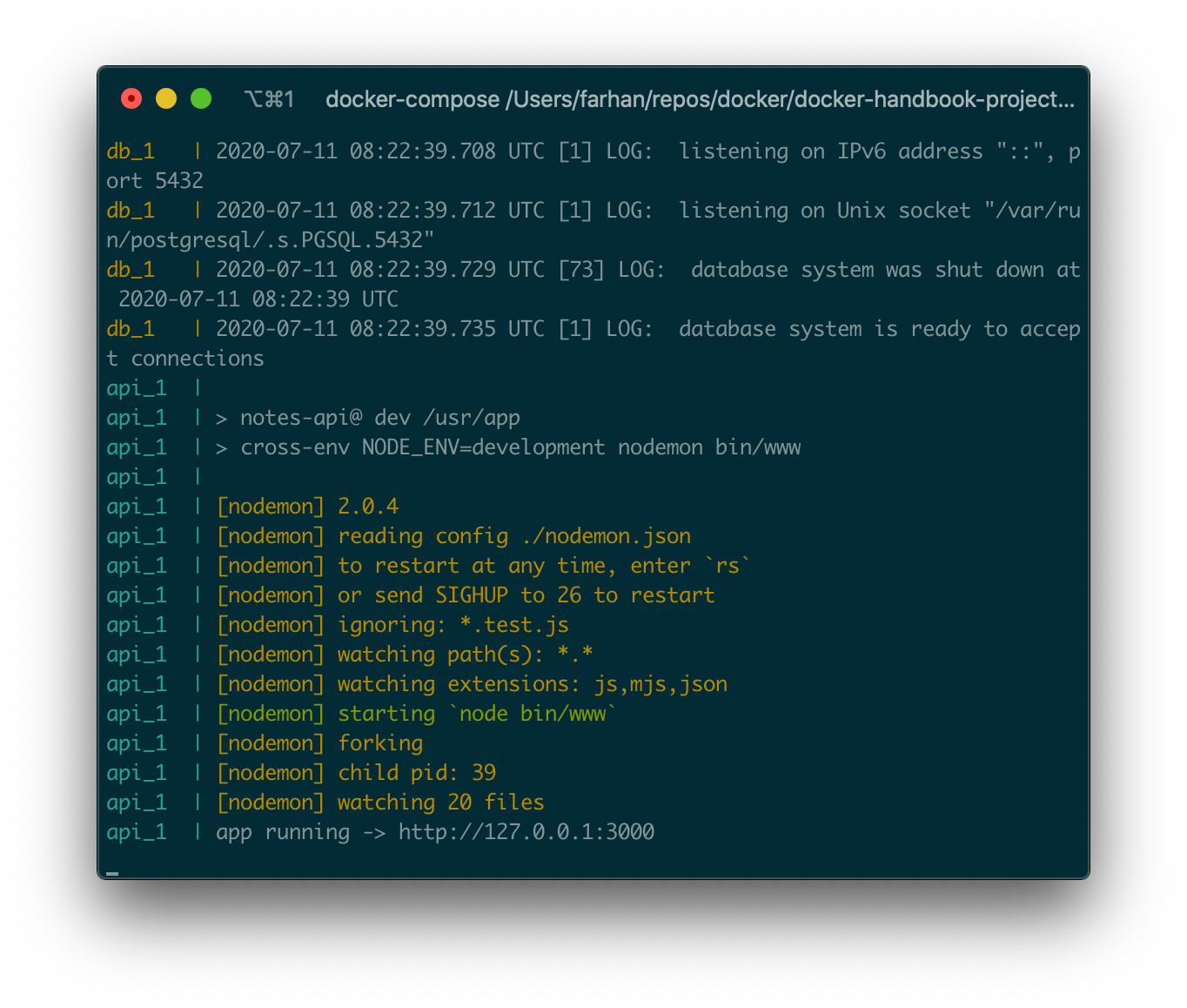
コマンドを実行すると、docker-compose.ymlファイルを読み込み、各サービスのコンテナを作成して開始します。先に進んで、コマンドを実行してください。サービスの数によっては、起動プロセスに時間がかかる場合があります。
完了すると、ターミナルウィンドウのすべてのサービスからのログが表示されます。
アプリケーションはhttp://127.0.0.1:3000アドレスで実行されている必要があり、アクセスすると、次のようなJSONがレスポンスとして表示されます。
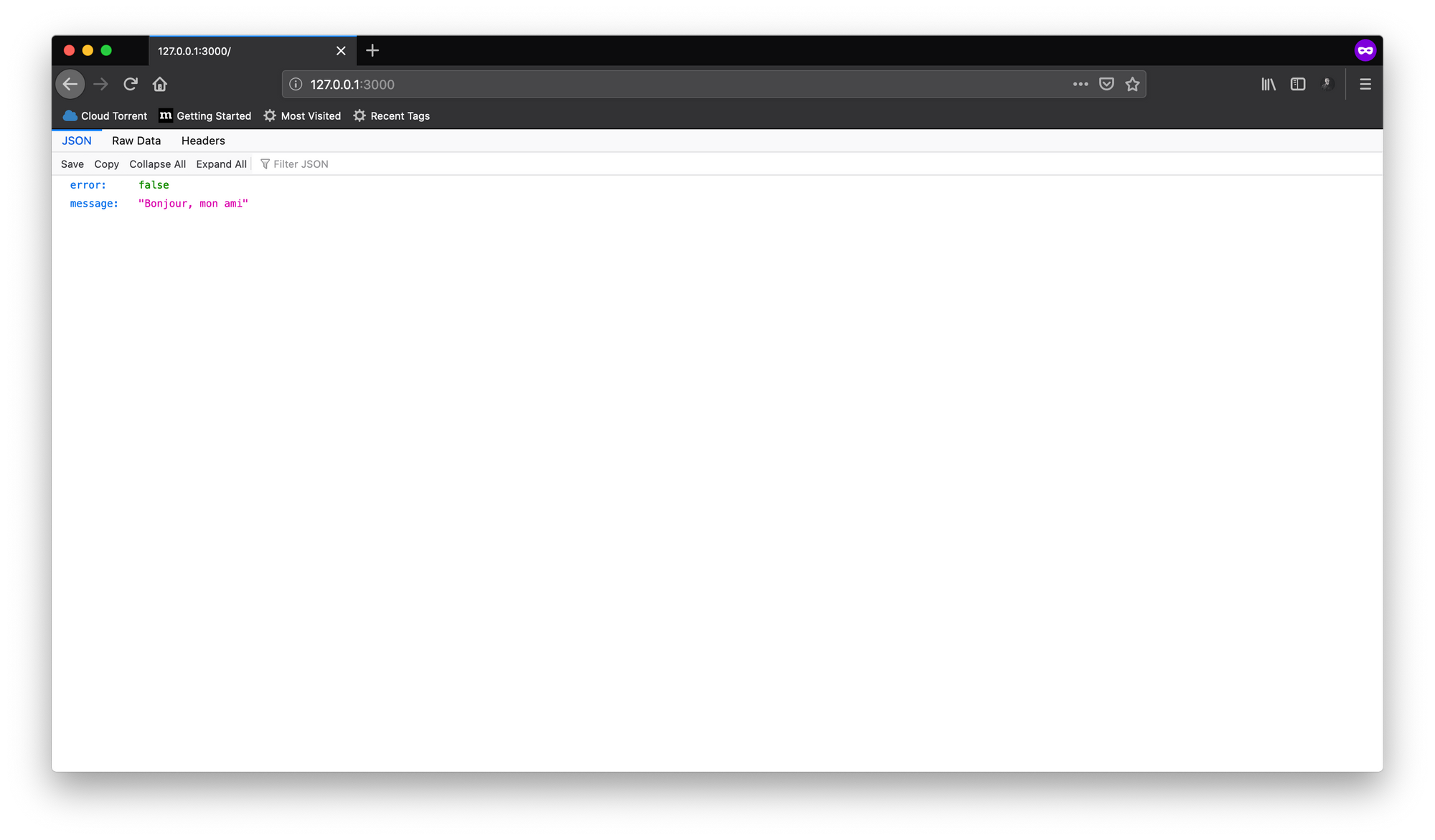
APIには完全なCRUD機能が実装されています。エンドポイントについて知りたい場合は、/tests/e2e/api/routes/notes.test.jsファイルを参照してください。
upコマンドは、サービスのイメージが存在しない場合に自動的に作成します。イメージの再構築を強制したい場合は、upコマンドで--buildオプションを使用できます。ターミナルウィンドウを閉じるか、ctrl + cを押すと、サービスを停止できます。
デタッチモードでサービスを実行する
すでに述べたように、サービスはコンテナであり、他のコンテナと同様に、サービスはバックグラウンドで実行できます。デタッチモードでサービスを実行するには、upコマンドで-dまたは--detachオプションを使用できます。
現在のアプリケーションをデタッチモードで起動するには、次のコマンドを実行します。
docker-compose up -d
今回は、前のサブセクションで見た長いテキストの壁は表示されません。
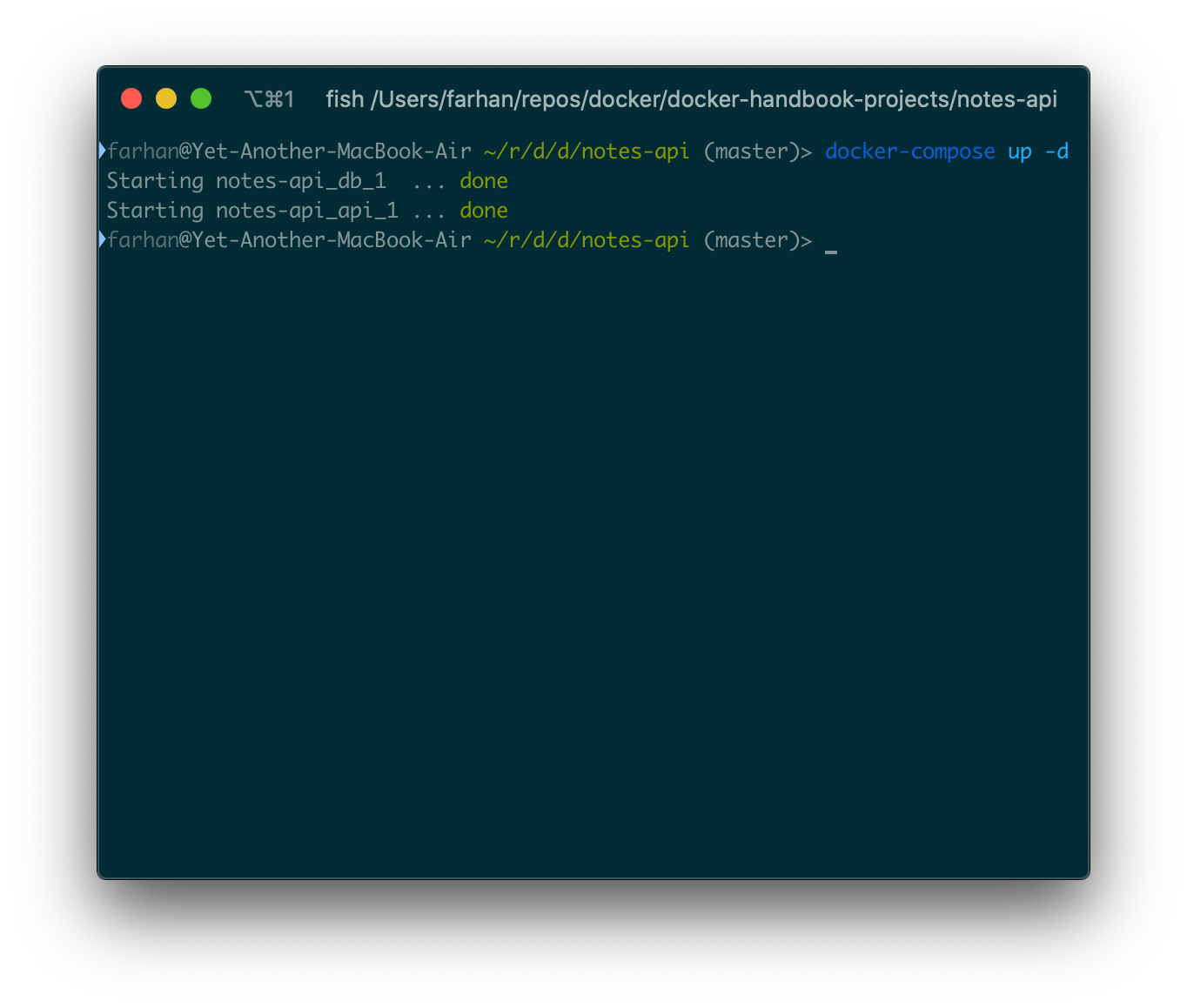
なおhttp://127.0.0.1:3000でAPIにアクセスできるはずです。
サービスの一覧表示
docker psコマンドと同様に、Composeには独自のpsコマンドがあります。主な違いは、docker-compose psコマンドは特定のアプリケーションのコンテナ部分のみを一覧表示することです。notes-apiアプリケーションの一部として実行されているすべてのコンテナを一覧表示するには、プロジェクトルートで次のコマンドを実行します。
docker-compose ps
プロジェクトディレクトリ内でコマンドを実行することが重要です。それ以外の場合は実行されません。コマンドからの出力は次のようになります。
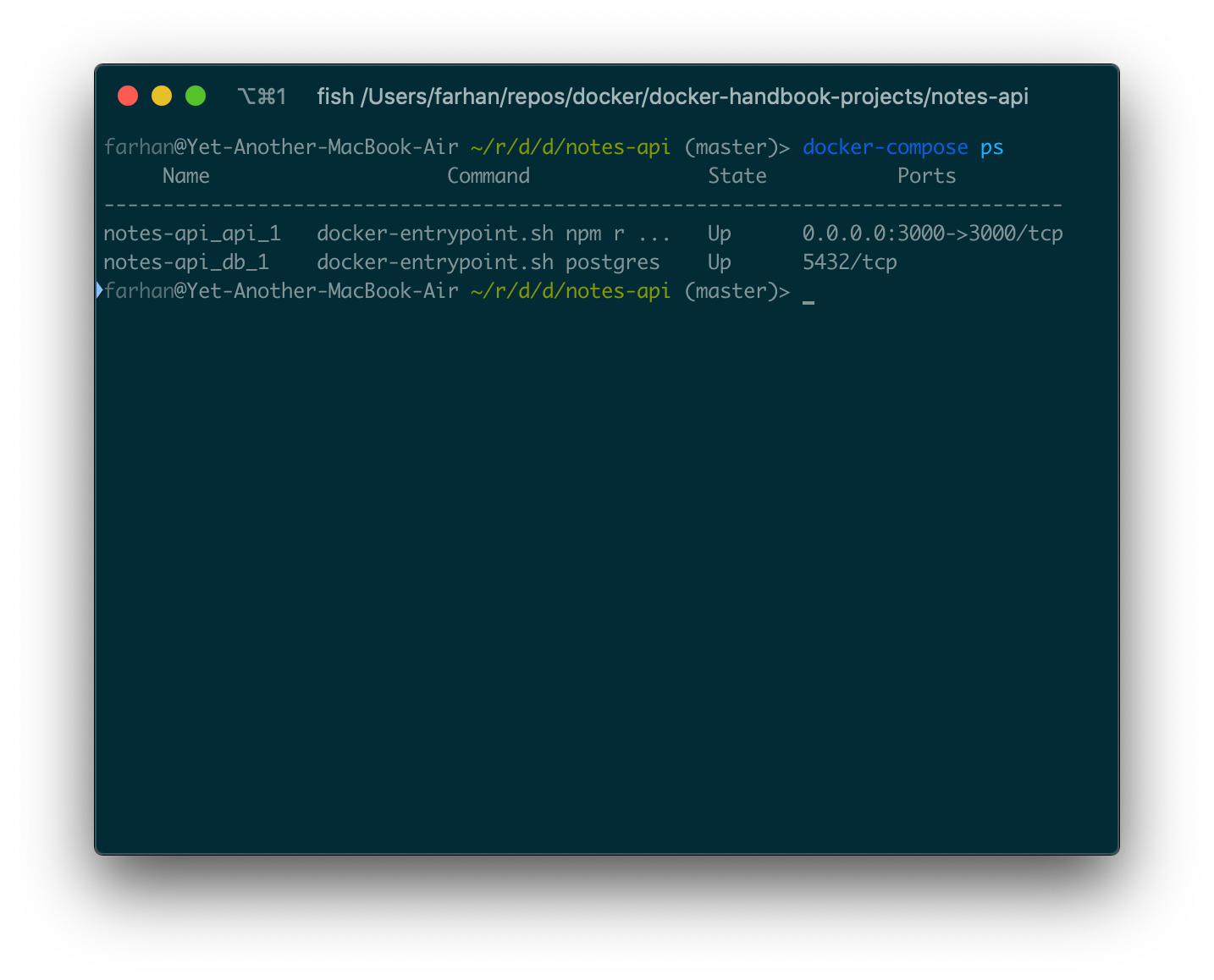
Composeのpsコマンドはデフォルトで任意の状態のサービスを表示します。-aや--allなどのオプションを使用する必要はありません。
実行中のサービス内でコマンドを実行する
notes-apiアプリケーションが実行中で、dbサービス内のpsqlCLIアプリケーションにアクセスするとします。それを行うためにexecと呼ばれるコマンドがあります。コマンドの一般的な構文は次のとおりです。
docker-compose exec <サービス名> <コマンド>
サービス名はdocker-compose.ymlファイルにあります。psqlCLIアプリケーションを起動するための一般的な構文は次のとおりです。
psql <データベース> <ユーザー名>
データベース名がnotesdbで、ユーザーがpsqlであるdbサービス内でpsqlアプリケーションを開始するには、次のコマンドを実行する必要があります。
docker-compose exec db psql notesdb postgres
psqlアプリケーションに直接アクセスする必要があります。
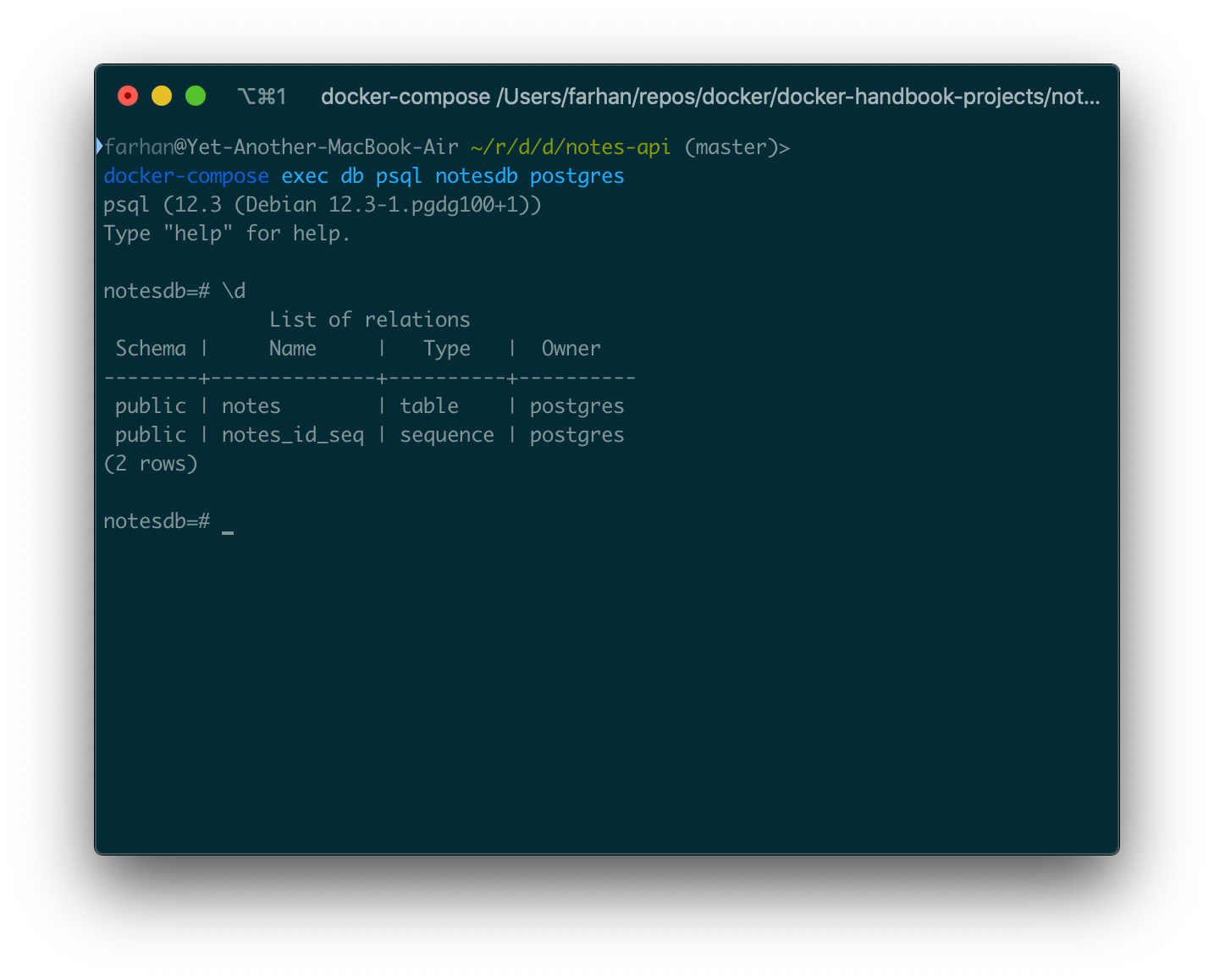
ここで有効なpostgresコマンドを実行できます。プログラムを終了するには、\qと入力してEnterキーを押します。
実行中のサービス内でシェルを開始する
execコマンドを使用して、実行中のコンテナ内でシェルを起動することもできます。コマンドの一般的な構文は次のとおりです。
docker-compose exec <サービス名> sh
コンテナに付属している場合は、shの代わりにbashを使用できます。apiサービス内でシェルを開始するには、コマンドは次のようにする必要があります。
docker-compose exec api sh
これにより、apiサービス内のシェルに直接アクセスできます。
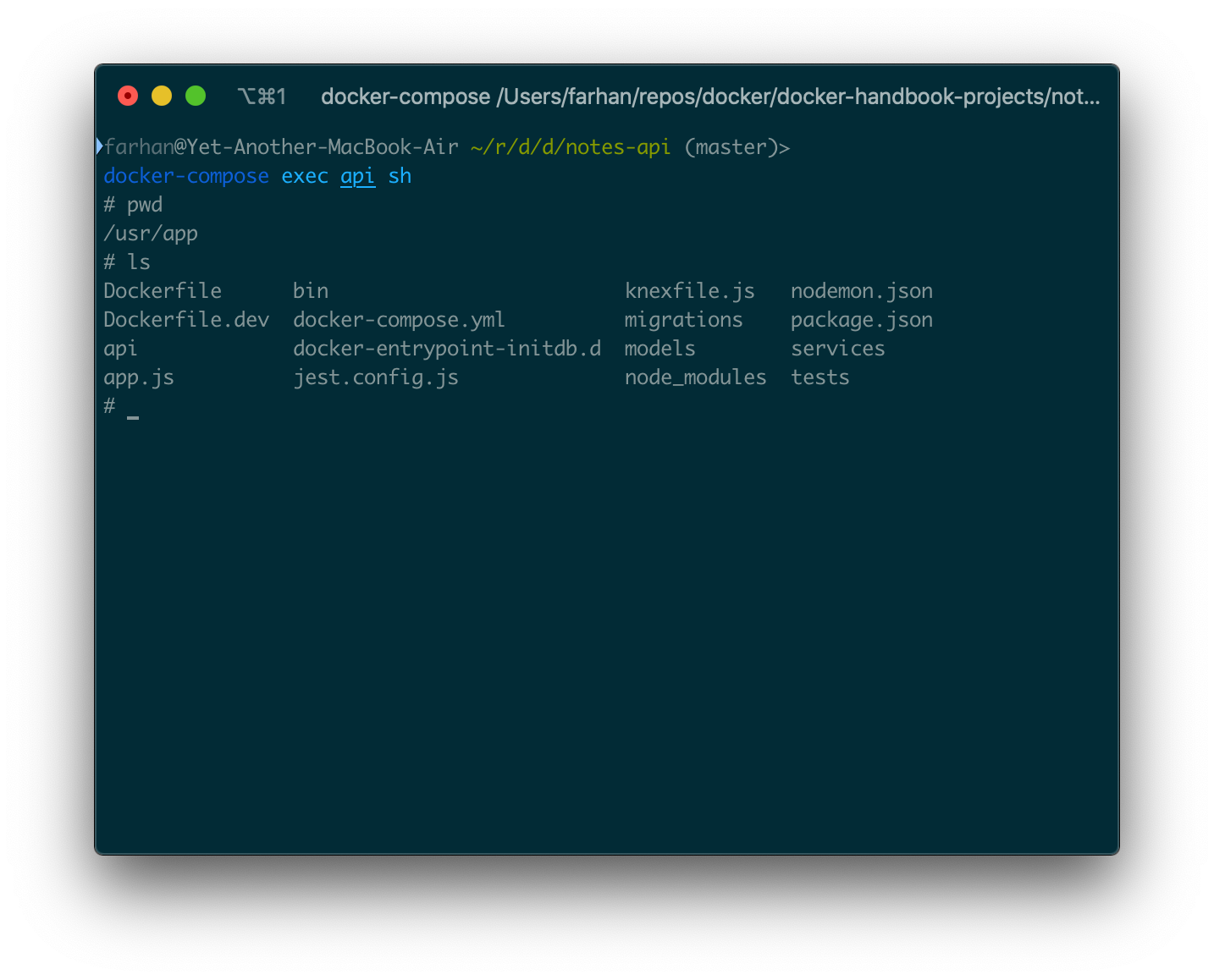
そこで、任意の有効なシェルコマンドを実行できます。exitコマンドを実行することで終了できます。
実行中のサービスからログにアクセスする
コンテナからログを表示する場合は、ダッシュボードが非常に役立ちます。
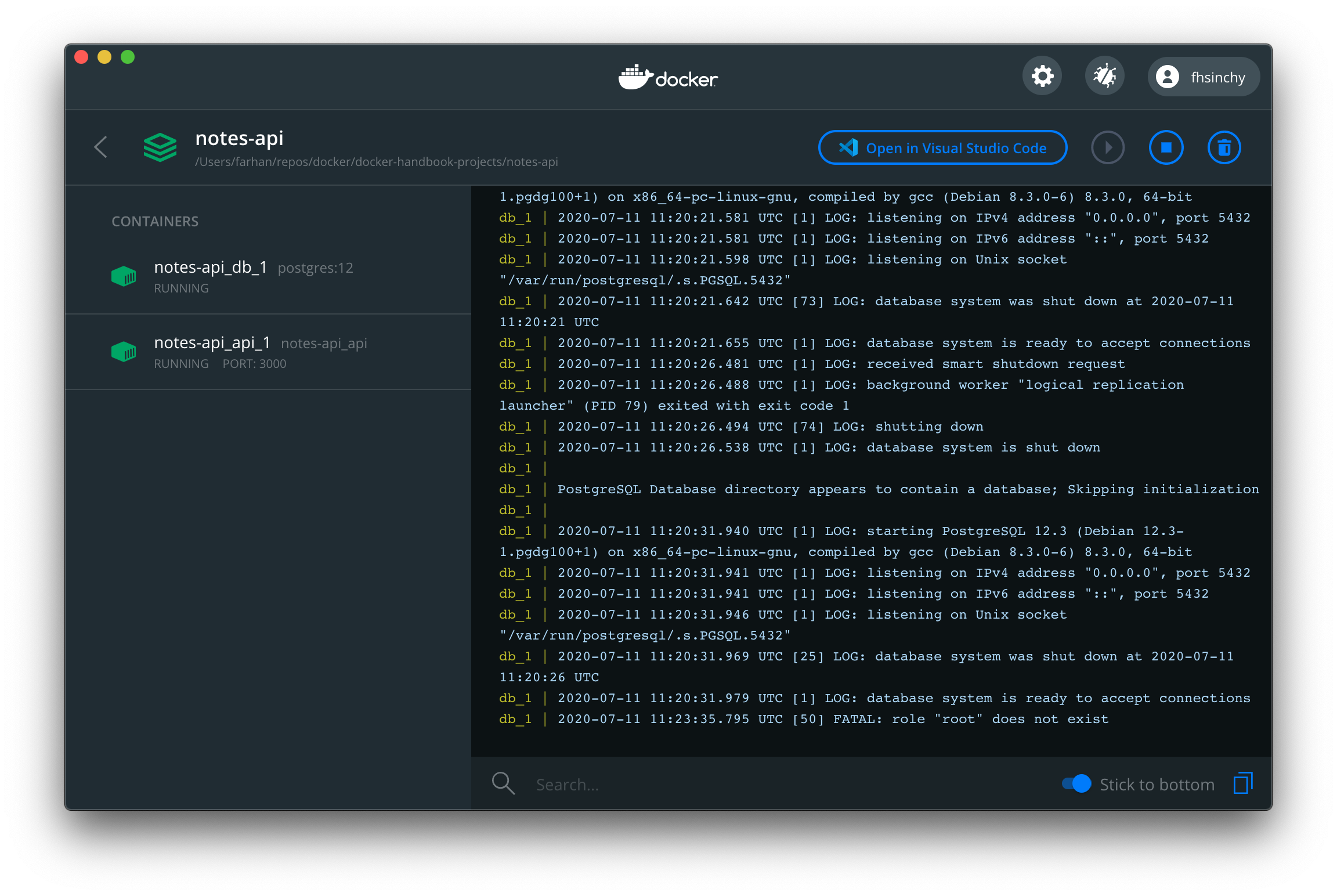
また、logsコマンドを使用して、実行中のサービスからログを取得することもできます。コマンドの一般的な構文は次のとおりです。
docker-compose logs <サービス名>
apiサービスからログにアクセスするには、次のコマンドを実行します。
docker-compose logs api
ターミナルウィンドウにテキストの壁が表示されるはずです。
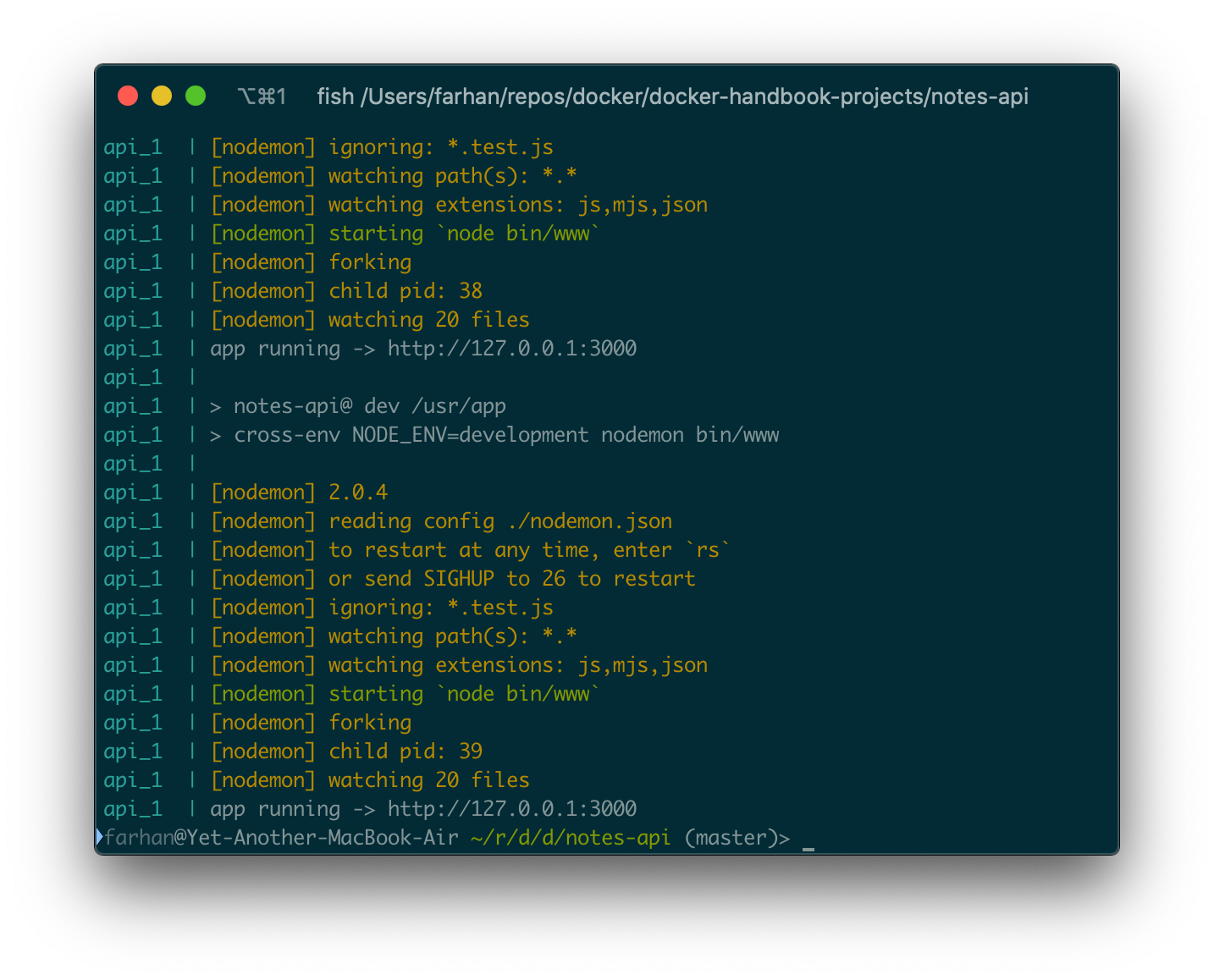
これはログ出力の一部にすぎません。-fまたは--followオプションを使用すると、サービスの出力ストリームにフックしてリアルタイムでログを取得できます。以降のログは、ctrl + cを押すかウィンドウを閉じて終了しない限り、ターミナルに即座に表示されます。ログウィンドウを終了しても、コンテナは実行を続けます。
実行中のサービスを停止する
ターミナル上で実行されているサービスは、ターミナルウィンドウを閉じるか、ctrl + cを押すことで停止できます。バックグラウンドでサービスを停止するには、いくつかのコマンドを使用できます。一つ一つ説明していきます。
docker-compose stop-SIGTERMシグナルを送信することにより、実行中のサービスを適切に停止しようとします。サービスが制限時間内に停止しない場合、SIGKILLシグナルが送信されます。docker-compose kill-SIGKILLシグナルを送信して実行中のサービスを即座に停止します。SIGKILLシグナルは受信者が無視することはできません。docker-compose down-SIGTERMシグナルを送信して実行中のサービスを適切に停止しようとし、その後コンテナを削除します。
サービスのコンテナを保持したい場合は、stopコマンドを使用できます。コンテナも削除する場合は、downコマンドを使用します。
フルスタックアプリケーションの作成
このサブセクションでは、ノートAPIにフロントエンドアプリケーションを追加し、それを完全なアプリケーションに変換します。このサブセクションのDockerfile.devファイル(nginxサービスのファイルを除く)は、前のサブセクションですでに見た他のファイルと同一であるため、説明しません。
プロジェクトコードリポジトリのクローンを作成した場合は、fullstack-notes-applicationディレクトリ内に移動します。プロジェクトルート内の各ディレクトリには、各サービスのコードと対応するDockerfileが含まれています。
docker-compose.ymlファイルから始める前に、アプリケーションがどのように機能するかを示す図を見てみましょう。

以前のように直接リクエストを受け入れる代わりに、このアプリケーションでは、すべてのリクエストが最初にNginxサーバーによって受信されます。Nginxは、リクエストされたエンドポイントに/apiが含まれているかどうかを確認します。はいの場合、Nginxはリクエストをバックエンドにルーティングします。そうでない場合、Nginxはリクエストをフロントエンドにルーティングします。
これを行う理由は、フロントエンドアプリケーションを実行すると、コンテナ内では実行されないためです。コンテナから提供されるブラウザで実行されます。その結果、Composeネットワークが期待どおりに機能せず、フロントエンドアプリケーションがapiサービスを見つけることができません。
一方、nginxはコンテナ内で実行され、アプリケーション全体でさまざまなサービスと通信できます。
ここではNginxの構成については触れません。そのトピックは、この記事の範囲外ですが興味があれば/nginx/default.confファイルを読んでみてください。/nginx/Dockerfile.devのコードは次のとおりです。
FROM nginx:stable COPY ./default.conf /etc/nginx/conf.d/default.conf
コンテナ内の設定ファイルを/etc/nginx/conf.d/default.confにコピーするだけです。
使い慣れたサービスを定義して、docker-compose.ymlファイルの記述をしてみましょう。dbおよびapiサービス。プロジェクトルートにdocker-compose.ymlファイルを作成し、そこに次のコードを配置します。
version: "3.8"
services:
db:
image: postgres:12
volumes:
- ./docker-entrypoint-initdb.d:/docker-entrypoint-initdb.d
environment:
POSTGRES_PASSWORD: 63eaQB9wtLqmNBpg
POSTGRES_DB: notesdb
api:
build:
context: ./api
dockerfile: Dockerfile.dev
volumes:
- /usr/app/node_modules
- ./api:/usr/app
environment:
DB_CONNECTION: pg
DB_HOST: db ## データベースサービスと同じ名前を指定
DB_PORT: 5432
DB_USER: postgres
DB_DATABASE: notesdb
DB_PASSWORD: 63eaQB9wtLqmNBpg
ご覧のとおり、これら2つのサービスは前のサブセクションとほぼ同じです。唯一の違いは、apiサービスのcontextです。これは、そのアプリケーションのコードがapiという名前の専用ディレクトリ内にあるためです。また、サービスを直接公開したくないため、ポートマッピングはありません。
次に定義するサービスはclientサービスです。次のコードを構成ファイルに追加します。
##
## インデントは調整してください
##
client:
build:
context: ./client
dockerfile: Dockerfile.dev
volumes:
- /usr/app/node_modules
- ./client:/usr/app
environment:
VUE_APP_API_URL: /api
サービスにclientという名前を付けます。buildブロック内では、/clientディレクトリをcontextとして設定し、それにDockerfile名を付けています。
ボリュームのマッピングは、前のセクションで見たものと同じです。node_modulesディレクトリ用の1つの匿名ボリュームとプロジェクトルート用の1つの名前付きボリュームです。
environtment内のVUE_APP_API_URL変数の値は、clientからapiサービスへの各リクエストに追加されます。このようにして、Nginxは異なるリクエストを区別し、それらを適切に再ルーティングすることができます。
apiサービスと同様に、このサービスも公開したくないため、ここにはポートマッピングはありません。
アプリケーションの最後のサービスはnginxサービスです。これを定義するには、次のコードを構成ファイルに追加します。
##
## インデントを調整してください
##
nginx:
build:
context: ./nginx
dockerfile: Dockerfile.dev
ports:
- 80:80
Dockerfile.devの内容はすでに話しました。サービスにはnginxという名前を付けます。buildブロック内では、/nginxディレクトリをcontextとして設定し、それにDockerfile名を付けています。
すでに図で示したように、このnginxサービスはすべてのリクエストを処理します。したがって、それを公開する必要があります。Nginxはデフォルトでポート80番で実行されます。コンテナ内のポート80番をホストシステムのポート80番にマッピングしています。
docker-compose.ymlファイルが完成したので、サービスを実行します。次のコマンドを実行して、すべてのサービスを開始します。
docker-compose up
ここでhttp://localhost:80にアクセスしてみましょう!
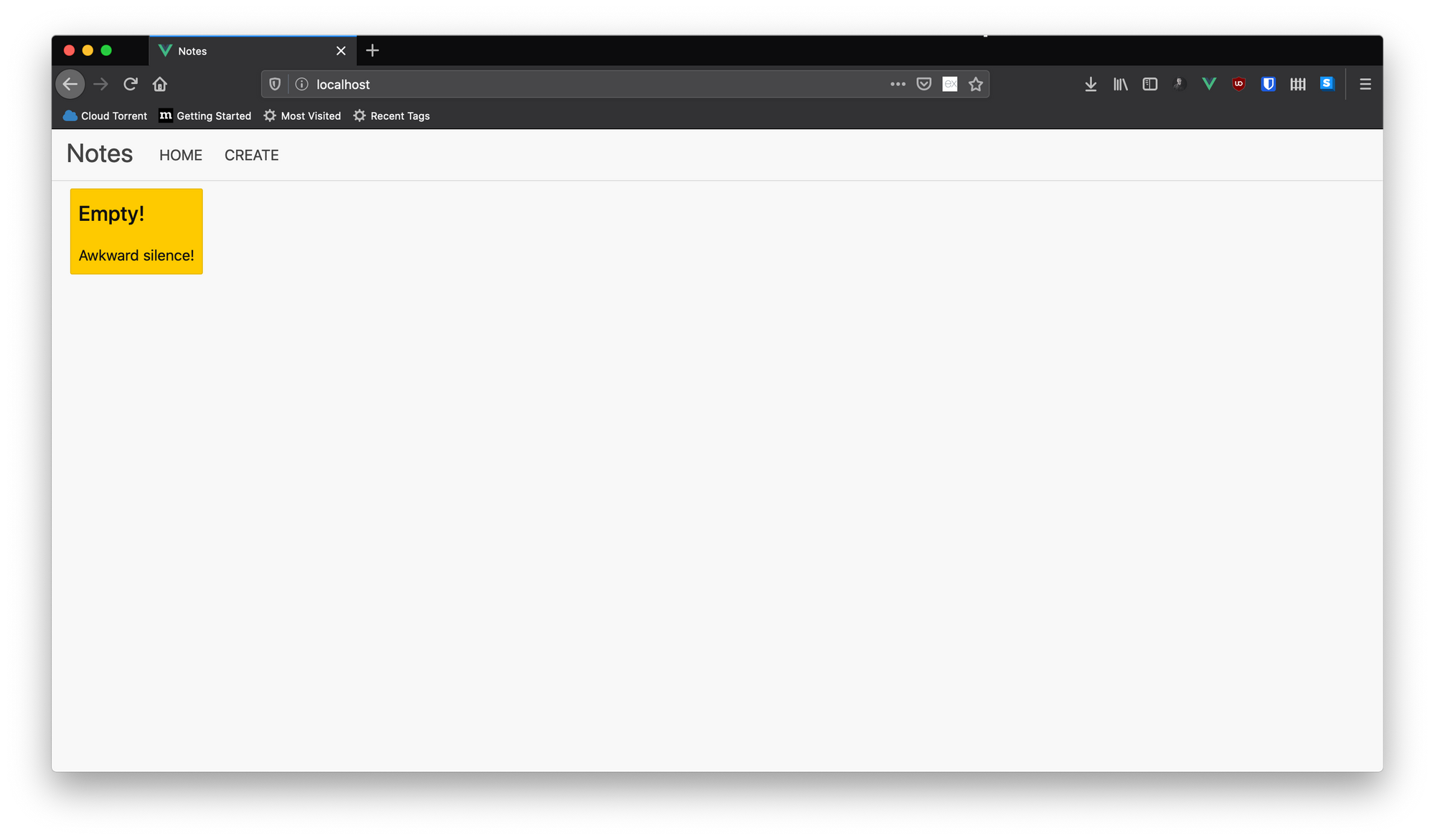
ノートを追加および削除して、アプリケーションが正しく動作するかどうかを確認してください。マルチコンテナアプリケーションはこれよりもはるかに複雑になる可能性がありますが、この記事ではこれで十分です。
まとめ
この記事を読んでくださった皆さんに心から感謝します。あなたがこの時間を楽しんで、Dockerのすべての本質を学んだことを願っています。
今後の最新記事をキャッチアップするなら、フォローしてください。@frhnhsin✌
筆者紹介
Farhan Hasin Chowdhury
レストラン管理システムを開発するFoodQoでテックリードを務める傍ら、NPOで運営されるプログラミング情報コミュニティ「freeCodeCamp」にてライター活動も行っている。
翻訳者紹介
satoru
大学を半年で中退後、Webエンジニアとして就職。チームラボやダイヤモンドメディアを経てシリコンバレーを訪問。世界的な企業でエンジニアリングを学び、現在は教会にコントリビュートするエンジニアとしてフリーランスで活動している。このブログの運営者でもある。